

Nowadays, everything is about automation. Software testing is no exception. After an introduction, we will create and run utPLSQL tests with Oracle SQL Developer for a fictitious user story. Our tests will cover a PL/SQL package, a virtual column, two database triggers and a view. The full code samples can be found here.
This blog post is based on my German article Testen mit utPLSQL – Leicht gemacht mit SQL Developer, published in issue 4/2022 of the Red Stack Magazin.
What is Test Automation?
Here’s the definition from the English Wikipedia page:
Test automation is the use of software separate from the software being tested to control the execution of tests and the comparison of actual outcomes with predicted outcomes.
If the actual results match the expected results, then the tests are successful. An important aspect of test automation is the prior definition of expected results. Expected results are simply requirements. In other words, we use automated tests to check whether the requirements are met.
Why Do We Need Automated Tests?
The use of agile methods and the associated shorter release cycles mean that we need to test software more frequently. In a CI/CD environment, automated tests can be executed directly after a commit in a version control system. Through this continuous testing, the state of the software quality is constantly available. In case of deviations, the possible causes can be identified more quickly due to the shorter intervals between tests. In addition, the changes, since the last successful test run, are still present in the minds of the developers. All this simplifies troubleshooting.
When software is tested only semi-automatically or manually, this leads to higher costs, higher risks, delivery delays or quality problems. It is simply not efficient to perform automatable tasks manually.
Repeating automated tests is cheap. Unlike manual tests, there is no reason to compromise. This is especially important for central components of a software solution. We need to ensure that changes do not have any unwanted effects on other parts of the software solution.
Do Automated Tests Have Downsides?
In the end, an automated test is also software that needs to be maintained. Tests that are not reliable are especially problematic. These are so-called “flaky” tests, which sometimes fail, but if you repeat them often enough, deliver the expected result. Such tests quickly do more harm than good. The more flaky tests there are, the higher the probability that the CI job will fail, resulting in manual activities.
What Can We Test in the Database?
Basically, every component of an application installed in the database can be tested automatically. These are, for example, object types, packages, procedures, functions, triggers, views and constraints.
We do not write tests for ordinary not null check constraints since we do not want to test the basic functionality of a database. However, it might be useful to test a complex expression of a virtual column or a complex condition of a check constraint. A view is based on a select statement. select statements can be quite complex even without PL/SQL units in the with_clause. Consequently, we also have the need to check whether views return the expected results.
Object types, packages, procedures, functions and triggers mainly contain code in PL/SQL. However, PL/SQL allows the embedding of various other languages such as SQL, C, Java or JavaScript. It goes without saying that these components should be tested with automated tests. This also applies to database triggers, which cannot be executed directly. Of course, it simplifies testing if the logic of the database triggers is stored in PL/SQL packages and database triggers only contain simple calls to package procedures.
What Is utPLSQL?
utPLSQL is a testing suite for code in the Oracle database and is based on concepts from other unit testing frameworks such as JUnit and RSpec. The figure below shows the components of the utPLSQL suite.

Core Testing Framework
The Core Testing Framework is installed in a dedicated schema of the Oracle database. All tables in this schema are used for temporary data or caching purposes. That means newer or older versions of utPLSQL can be installed at any time without data loss. Test suites are PL/SQL packages which are annotated with a special comment --%suite. These special comments are called annotations and provide utPLSQL with all information for test execution. utPLSQL uses different concepts to efficiently read the required data from the Oracle data dictionary views so that tests can be executed without noticeable time delay even in schemas with more than 40 thousand PL/SQL packages.
Development
The utPLSQL plugins for SQL Developer from Oracle and PL/SQL Developer from Allround Automations support database developers in creating, executing and debugging tests. Code coverage reports provide information about which code is covered by tests. These two plugins are provided by the utPLSQL team. Quest and JetBrains position utPLSQL as the standard for testing code in an Oracle database and support utPLSQL directly in their products TOAD and DataGrip.
Test Automation
utPLSQL uses reporters to produce the results of a test run in any number of output formats. The command line client or the Maven plugin can be used for this purpose. A popular output format is the JUnit since it is compatible with most tools in the CI/CD area. TeamCity and Team Foundation Server are supported by specific reporters. For code coverage, utPLSQL provides reporters for SonarQube, Coveralls and Cobertura. Thanks to the flexible reporter concept, utPLSQL can be integrated into any CI/CD environment. For example, in Jenkins, Bamboo, Azure DevOps, Travis CI, GitLab, GitHub Actions and many more.
Case Study And Solution Approach
We use a schema redstack with the known Oracle tables dept and emp. In the current sprint, the following user story from our HR manager is scheduled:
As a HR manager, I need a table with the key figures salary total, number of employees and average salary per department to assess fairness.
I interpret the requirement literally and create a table according to listing 1.
create table deptsal (
deptno number(2, 0) not null
constraint deptsal_pk primary key,
dname varchar2(14) not null,
sum_sal number(10, 2) not null,
num_emps number(4, 0) not null,
avg_sal number(7, 2)
generated always as (
case
when num_emps != 0 then
round(sum_sal / num_emps, 2)
else
0
end
) virtual
);I populate the table using a PL/SQL package procedure called “etl.refresh_deptsal”. The exact implementation is not so important. If you are interested you can find it here.
Test Suite and Test Run
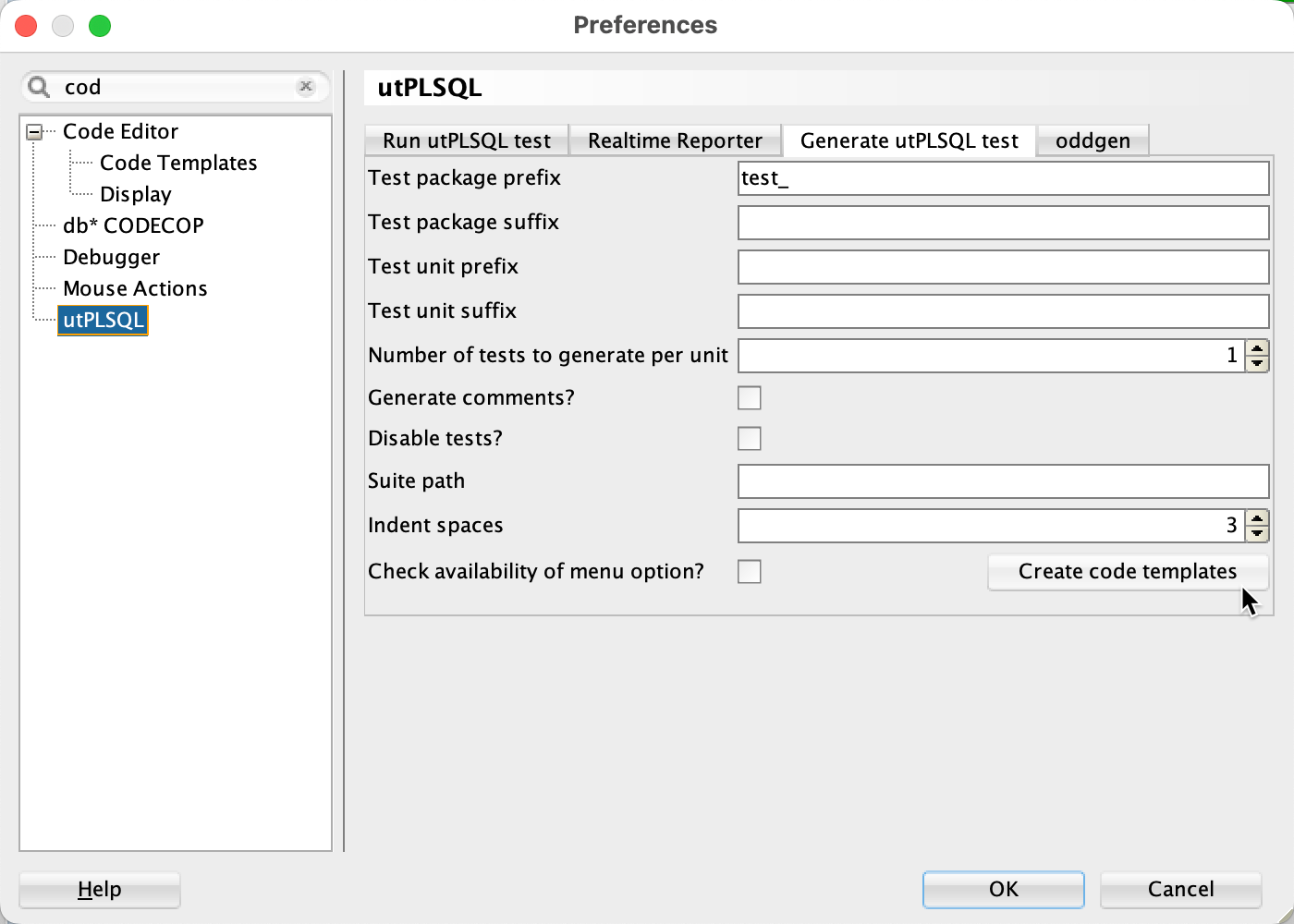
Writing the code before the test is not test-driven development. Anyway, I am a pragmatist and not a dogmatist. In the end, I feel the need to check if my code does what it should do. To execute the code, I use utPLSQL. The utPLSQL extension for SQL Developer helps me to do this. For example, I can generate the skeleton of a test suite based on my existing implementation or use the code templates to create a test package, a test package body or a test procedure. The following figure shows the utPLSQL preferences of the generator and the code templates in SQL Developer.
In a new worksheet, I entered ut_spec followed by Ctrl-Space to fill in the template for a test suite. Listing 2 shows the result.
create or replace package test_etl is
--%suite
--%test
procedure refresh_deptsal;
end test_etl;
/The annotation --%suite identifies the package test_etl as a test suite. The annotation for the package must follow the keyword is or as. Up to the first empty line, all annotations are assigned to the package. The annotation --%test marks the procedure refresh_deptsal as a test. A test suite can consist of any number of tests. Tests can optionally be grouped with the annotations --%context(<name>) and --%endcontext. utPLSQL supports more than 20 annotations, which are available as snippets in SQL Developer.
I can now run this test suite. Either via the context menu in the editor or on a node in the navigation tree. The following figure shows the utPLSQL test runner after the execution of the test.
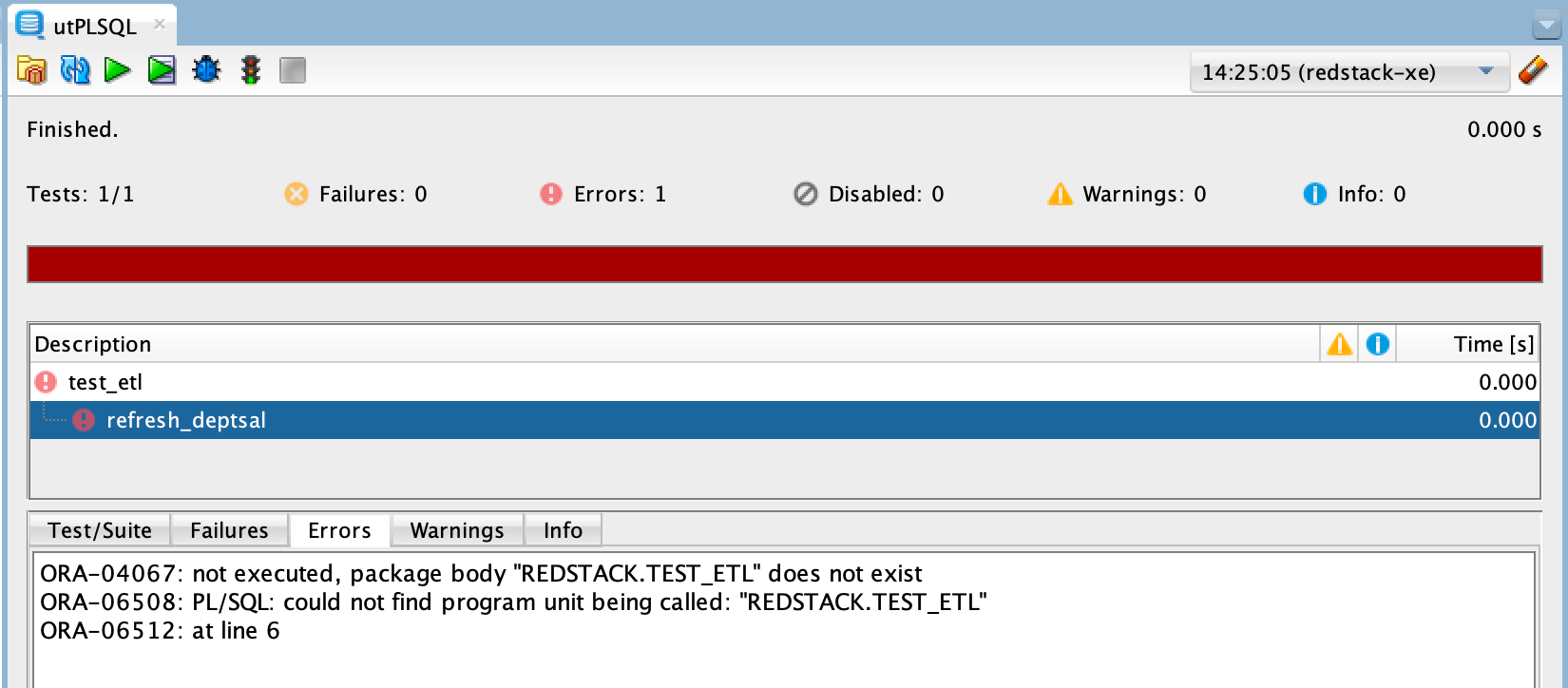
The test runner uses two additional temporary connections to the database in the background. This way the SQL Developer is never blocked, which is very helpful, especially for more time-consuming tests. It is even possible to run independent tests simultaneously.
Test Implementation and Test Run
The test refresh_deptsal produces an error. The reason is obvious. The implementation of the test is missing. So, let’s create the missing package body.
create or replace package body test_etl is
procedure refresh_deptsal is
c_actual sys_refcursor;
c_expected sys_refcursor;
begin
-- act
etl.refresh_deptsal;
-- assert;
open c_actual for select * from deptsal;
open c_expected for
select d.deptno,
d.dname,
nvl(sum(e.sal), 0) as sum_sal,
nvl(count(e.empno), 0) as num_emps,
nvl(trunc(avg(e.sal), 2), 0) as avg_sal
from dept d
left join emp e
on e.deptno = d.deptno
group by d.deptno, d.dname;
ut.expect(c_actual).to_equal(c_expected)
.join_by('DEPTNO');
end refresh_deptsal;
end test_etl;
/The implementation of the test in listing 3 uses the AAA pattern. It stands for Arrange-Act-Assert. In the arrange step, the test is prepared. Here, this step is missing since the test is based on existing data. In the act step, we execute the code under test. And in the assert step, we compare the actual result with the expected result. utPLSQL provides a variety of type-safe matchers for this purpose. In this case, we compare two cursors. The data types as well as the contents of the columns are compared for all rows. The figure below shows the result after our next test run.
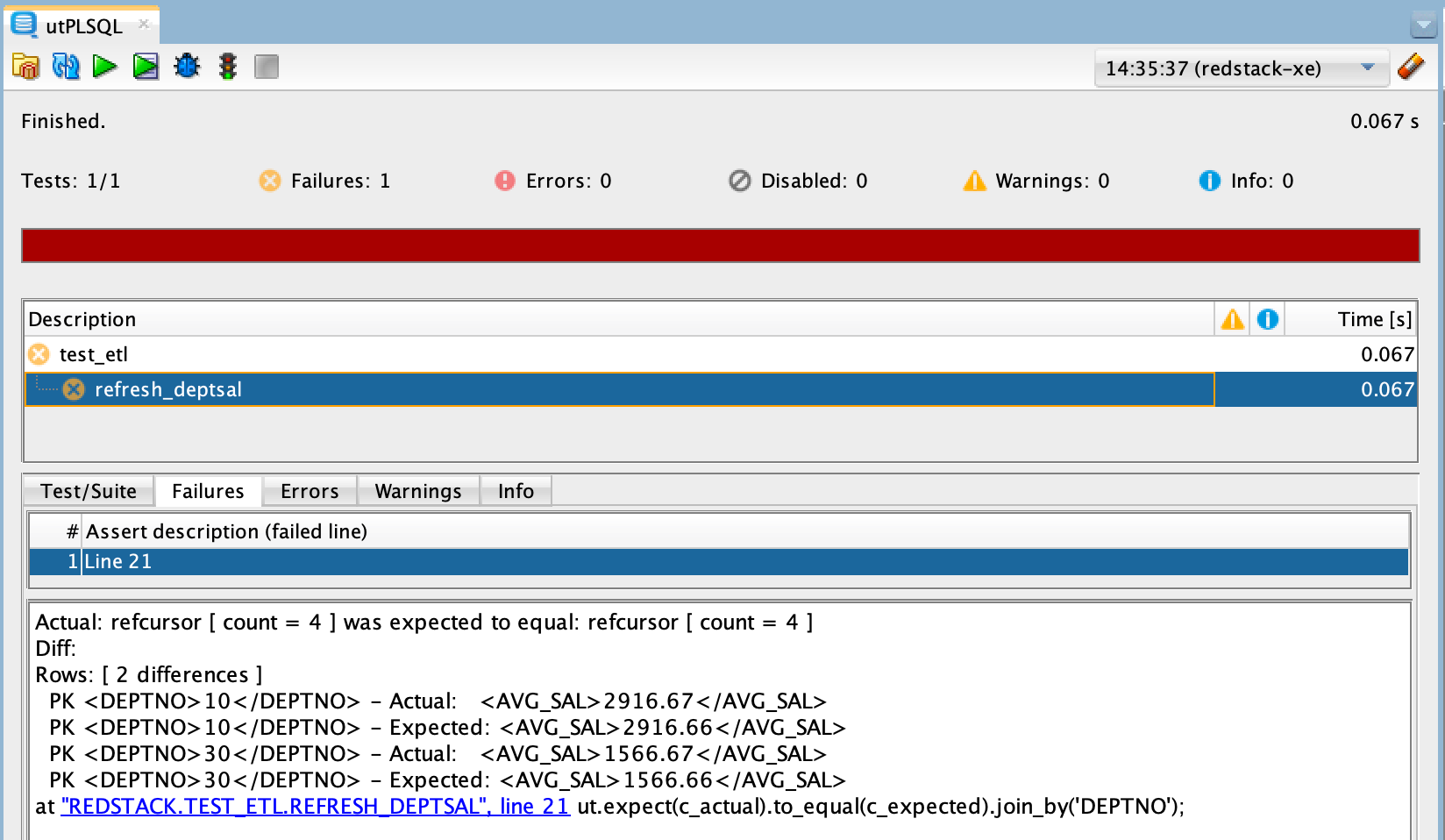
Now the test run produces a failure. This means that the test does not deliver the expected result. In the `Failures` tab of the test runner, the details are displayed. We see that we expected 4 rows and also got 4 rows. However, there are differences in the column avg_sal for two records. This looks like a rounding difference. Obviously, we round up in the code and round down in the test. What is correct now? I would say rounding up is common and that’s why we should adjust the test. After replacing trunc with round in the test implementation (see line 16 in listing 3), the test will complete successfully.
Test Cases for Insert, Update and Delete
The test refresh_deptsal expects data in the tables dept and emp If the tables are empty, the test still works. This is not wrong, but it shows that the quality of the test is strongly dependent on our existing data. Also, we run the risk that the test code for the assert will mirror the implementation and any errors will be repeated. Listing 4 shows an additional test based on our own test data.
procedure refresh_deptsal_upd_dept_and_emp is
c_actual sys_refcursor;
c_expected sys_refcursor;
begin
-- arrange
insert into dept (deptno, dname, loc)
values (-10, 'utPLSQL', 'Winterthur');
insert into emp (empno, ename, job, hiredate, sal, deptno)
values (-1, 'Jacek', 'Developer', trunc(sysdate), 4700, -10);
insert into emp (empno, ename, job, hiredate, sal, deptno)
values (-2, 'Sam', 'Developer', trunc(sysdate), 4300, -10);
-- act
update dept set dname = 'Testing' where deptno = -10;
update emp set sal = 5000 where empno = -2;
-- assert
open c_actual for select * from deptsal where deptno = -10;
open c_expected for
select -10 as deptno,
'Testing' as dname,
9700 as sum_sal,
2 as num_emps,
4850 as avg_sal
from dual;
ut.expect(c_actual).to_equal(c_expected).join_by('DEPTNO');
end refresh_deptsal_upd_dept_and_emp;First, a department -10 is created with employees -1 and -2. Then the salaries of these two employees are adjusted. The expected results are based entirely on literals. Real identifiers are often positive. The use of negative values makes the tests independent of existing data. utPLSQL automatically sets a savepoint before running a test. At the end of the test, a rollback to this savepoint is performed. However, if a commit occurs somewhere, the test data with negative identifiers are quickly found and deleted.
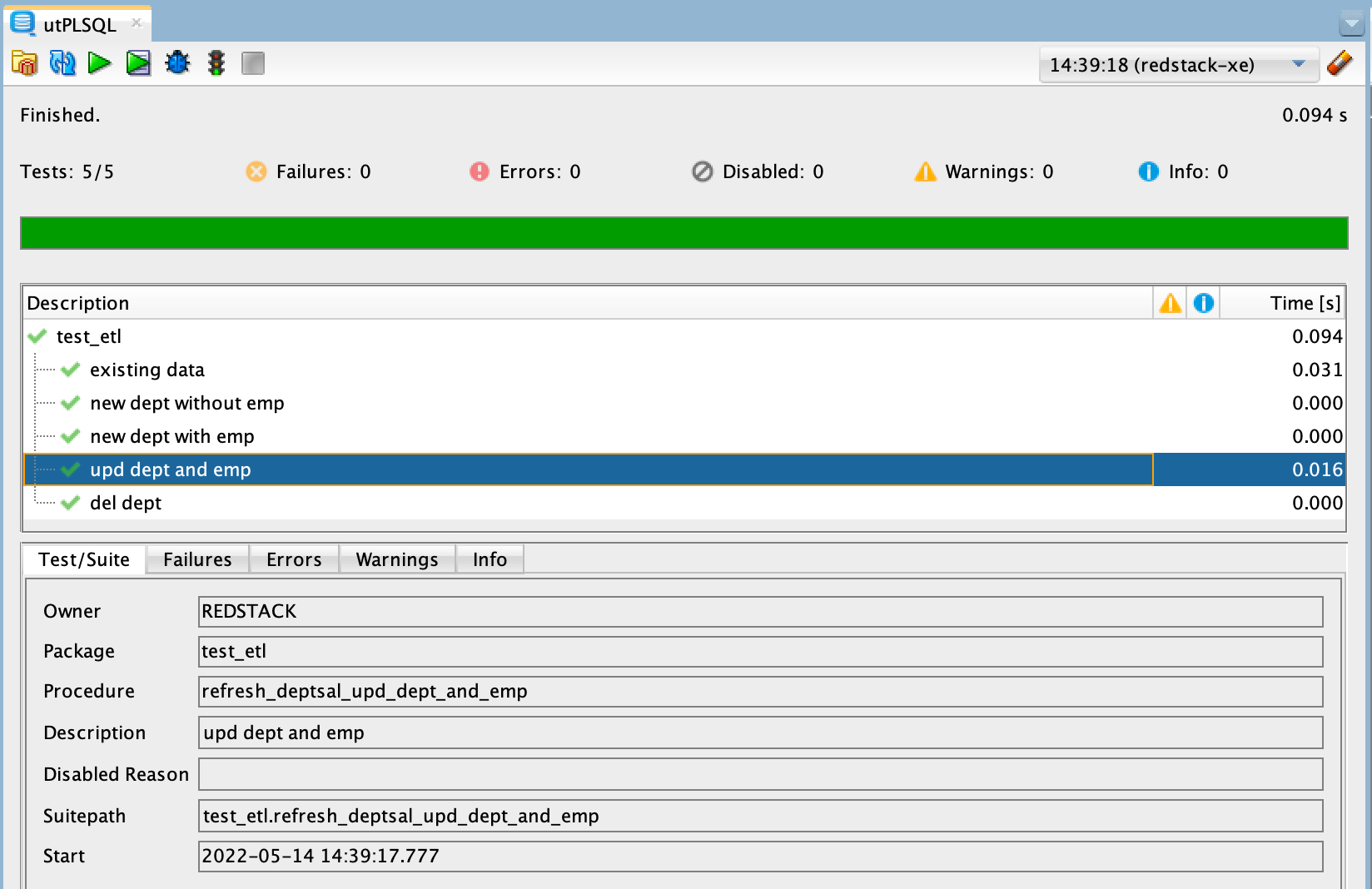
The next figure shows the successful execution of further tests, which I created here.
Automatic Refresh
The table deptsal is updated by calling etl.refresh_deptsal. We can fire this call using database triggers. Listing 5 shows how.
create or replace trigger dept_as_iud
after insert or update or delete on dept
begin
etl.refresh_deptsal;
end;
/
create or replace trigger emp_as_iud
after insert or update or delete on emp
begin
etl.refresh_deptsal;
end;
/Now the table deptsal is updated after each DML statement on tables emp and dept. To test if the database triggers work, I just need to remove the call of etl.refresh_deptsal in the existing tests. For the test on the existing data, I can fire a refresh with a technical update. And voilà, all tests run through without errors.
Time to commit the changes in the version control system, create a pull request, and perform a review.
Incorporating Review Comments
I showed the code to my colleague Lisa. She said that the solution is more complex than necessary and inefficient. On the one hand, the deptsal table is updated too often, for example before a rollbackor when more than one DML statement is used on the underlying tables within a transaction. On the other hand, providing a table is not absolutely necessary. Even though the HR manager specifically mentions “table” in her story, it is legitimate to use a view here instead of a table. Lisa thinks that with the amount of data we have, the performance should be good enough, especially if the query is limited to a few departments. Also, these metrics are not queried that often. A view would significantly reduce our code base and simplify maintenance.
Of course, Lisa is right. I can drop the table deptsal, the package etl and the database triggers. A simple view called deptsal, which is based on the fixed query in Listing 3, is sufficient here. But what do I do with my tests? – Nothing! They still describe the requirements, which have not changed, and therefore completed successfully. Unless I made a mistake when defining the view.
Refactoring is much easier with existing tests. Some people would argue that tests are what make safe refactoring possible.
Core Messages And Recommendations
The first steps with utPLSQL are the hardest. Make utPLSQL available in all your development and testing environments. For shared environments, ask your DBA for help. Install also the extension for SQL Developer, it is not a requirement, but it simplifies the work with utPLSQL considerably.
Start with small steps. Use utPLSQL to reproduce bugs or to test new requirements. After a short time you will experience how utPLSQL changes the way you code. You will write smaller units. You will isolate code that is difficult to test. This will make your code easier to test and easier to maintain.