


Introduction
The IslandSQL grammar now covers all DML statements. This means call, delete, explain plan, insert, lock table, merge, select and update.
In this episode, we will focus on new features in the Oracle Database 23c that can be used in insert, update, delete and merge statements. For the select statement see the last episode.
Table Value Constructor
The new table value constructor allows you to create rows on the fly. This simplifies statements. Furthermore, it allows you to write a single statement instead of a series of statements, which makes the execution in scripts faster. It can be used in the select, insert and merge statement.
Insert
drop table if exists d;
create table d (deptno number(2,0), dname varchar2(14), loc varchar2(13));
insert into d (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON');Table D dropped.
Table D created.
4 rows inserted.Merge
merge into d t
using (values
(10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON')
) s (deptno, dname, loc)
on (t.deptno = s.deptno)
when matched then
update
set t.dname = s.dname,
t.loc = s.loc
when not matched then
insert (t.deptno, t.dname, t.loc)
values (s.deptno, s.dname, s.loc);4 rows merged.Direct Joins for UPDATE and DELETE Statements
The new from_using_clause can be used in delete and update statements.
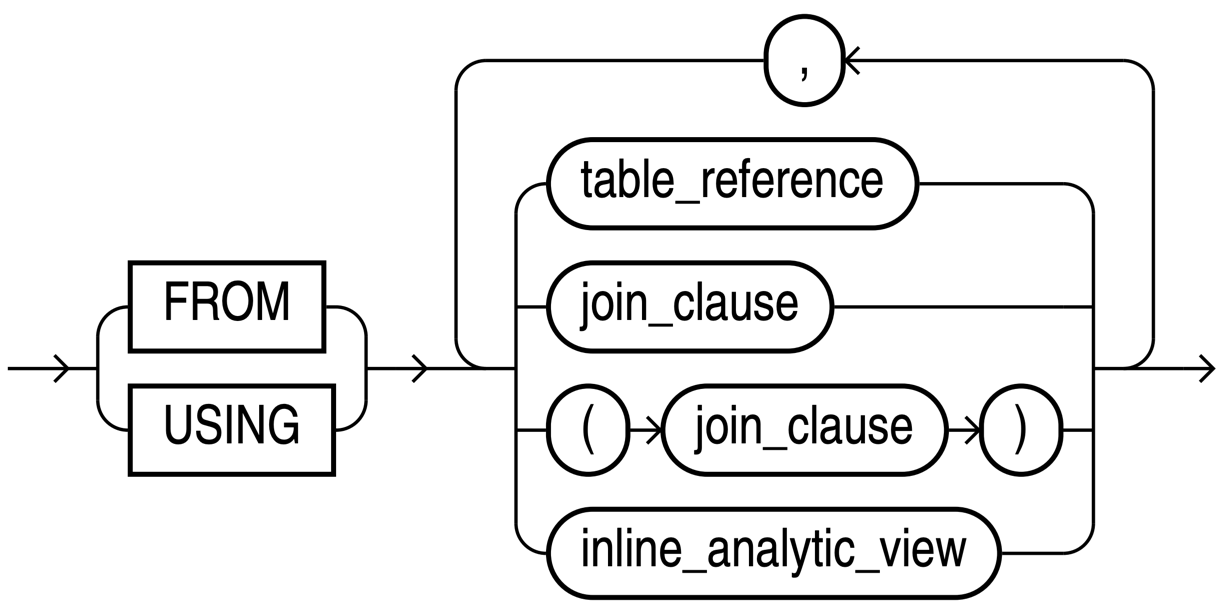
With this new clause, you can avoid a self-join and, as a result, the optimizer can produce a more efficient execution plan.
Delete
The next example is based on the HR schema. We delete all countries that are not used by any department. See line 3 for the from_using_clause. The join conditions and the filter criteria are part of the where_clause.
You cannot define the join condition for the table in the from_clause in the from_using_clause. This is a documented limitation. Furthermore, we cannot mix ANSI-92 join syntax with Oracle-style outer join syntax (see ORA-25156). As a result, we have to use the Oracle-style join syntax for all tables.
delete
from countries c
from locations l, departments d
where l.country_id (+) = c.country_id
and d.location_id (+) = l.location_id
and l.location_id is null
and d.department_id is null; 11 rows deleted.
--------------------------------------------------
| Id | Operation | Name |
--------------------------------------------------
| 0 | DELETE STATEMENT | |
| 1 | DELETE | COUNTRIES |
| 2 | FILTER | |
| 3 | HASH JOIN OUTER | |
| 4 | FILTER | |
| 5 | HASH JOIN OUTER | |
| 6 | INDEX FULL SCAN | COUNTRY_C_ID_PK |
| 7 | TABLE ACCESS FULL| LOCATIONS |
| 8 | TABLE ACCESS FULL | DEPARTMENTS |
--------------------------------------------------Having two from keywords in the delete statement is funny, but it does not make the statement easier to read. I therefore recommend rewriting the statement like this:
delete countries c
using locations l, departments d
where l.country_id (+) = c.country_id
and d.location_id (+) = l.location_id
and l.location_id is null
and d.department_id is null;11 rows deleted.
--------------------------------------------------
| Id | Operation | Name |
--------------------------------------------------
| 0 | DELETE STATEMENT | |
| 1 | DELETE | COUNTRIES |
| 2 | FILTER | |
| 3 | HASH JOIN OUTER | |
| 4 | FILTER | |
| 5 | HASH JOIN OUTER | |
| 6 | INDEX FULL SCAN | COUNTRY_C_ID_PK |
| 7 | TABLE ACCESS FULL| LOCATIONS |
| 8 | TABLE ACCESS FULL | DEPARTMENTS |
--------------------------------------------------Here’s an alternative, pre-23c-style delete statement without the from_using_clause. It is accessing the countries table twice, which might lead to a less efficient execution plan.
delete
from countries c1
where c1.country_id in (
select c2.country_id
from countries c2
left join locations l
on l.country_id = c2.country_id
left join departments d
on d.location_id = l.location_id
where l.location_id is null
and d.department_id is null
);11 rows deleted.
----------------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------------
| 0 | DELETE STATEMENT | |
| 1 | DELETE | COUNTRIES |
| 2 | INDEX FULL SCAN | COUNTRY_C_ID_PK |
| 3 | FILTER | |
| 4 | NESTED LOOPS OUTER | |
| 5 | FILTER | |
| 6 | NESTED LOOPS OUTER | |
| 7 | INDEX UNIQUE SCAN | COUNTRY_C_ID_PK |
| 8 | TABLE ACCESS BY INDEX ROWID BATCHED| LOCATIONS |
| 9 | INDEX RANGE SCAN | LOC_COUNTRY_IX |
| 10 | TABLE ACCESS BY INDEX ROWID BATCHED | DEPARTMENTS |
| 11 | INDEX RANGE SCAN | DEPT_LOCATION_IX |
----------------------------------------------------------------------Update
In this example, we increase the salaries of all employees in Germany and Canada by 20%. See lines 3 to 7 for the from_using_clause where we use ANSI-92 join syntax.
update employees e
set e.salary = e.salary * 1.2
using departments d
join locations l
on l.location_id = d.location_id
join countries c
on c.country_id = l.country_id
where d.department_id = e.department_id
and c.country_name in ('Germany', 'Canada');3 rows updated.
----------------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | EMPLOYEES |
| 2 | NESTED LOOPS | |
| 3 | NESTED LOOPS | |
| 4 | NESTED LOOPS | |
| 5 | NESTED LOOPS | |
| 6 | INDEX FULL SCAN | COUNTRY_C_ID_PK |
| 7 | TABLE ACCESS BY INDEX ROWID BATCHED| LOCATIONS |
| 8 | INDEX RANGE SCAN | LOC_COUNTRY_IX |
| 9 | TABLE ACCESS BY INDEX ROWID BATCHED | DEPARTMENTS |
| 10 | INDEX RANGE SCAN | DEPT_LOCATION_IX |
| 11 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX |
| 12 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES |
----------------------------------------------------------------------And here’s an alternative, pre-23c-style update statement without the from_using_clause. It is accessing the employees table twice, which might lead to a less efficient execution plan.
update employees e1
set e1.salary = e1.salary * 1.2
where e1.employee_id in (
select e2.employee_id
from employees e2
join departments d
on d.department_id = e2.department_id
join locations l
on l.location_id = d.location_id
join countries c
on c.country_id = l.country_id
where c.country_name in ('Germany', 'Canada')
);3 rows updated.
-----------------------------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | EMPLOYEES |
| 2 | HASH JOIN SEMI | |
| 3 | TABLE ACCESS FULL | EMPLOYEES |
| 4 | VIEW | VW_NSO_1 |
| 5 | NESTED LOOPS | |
| 6 | NESTED LOOPS | |
| 7 | NESTED LOOPS | |
| 8 | NESTED LOOPS SEMI | |
| 9 | VIEW | index$_join$_005 |
| 10 | HASH JOIN | |
| 11 | INDEX FAST FULL SCAN | LOC_COUNTRY_IX |
| 12 | INDEX FAST FULL SCAN | LOC_ID_PK |
| 13 | INDEX UNIQUE SCAN | COUNTRY_C_ID_PK |
| 14 | TABLE ACCESS BY INDEX ROWID BATCHED| DEPARTMENTS |
| 15 | INDEX RANGE SCAN | DEPT_LOCATION_IX |
| 16 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX |
| 17 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES |
-----------------------------------------------------------------------However, we can update an inline view. The Oracle database has supported this for a very long time (without a BYPASS_UJVC hint). There are some limitations, but otherwise, it works quite well. Here’s an example:
update (
select e.*
from employees e
join departments d
on d.department_id = e.department_id
join locations l
on l.location_id = d.location_id
join countries c
on c.country_id = l.country_id
where c.country_name in ('Germany', 'Canada')
)
set salary = salary * 1.2;3 rows updated.
---------------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | EMPLOYEES |
| 2 | NESTED LOOPS | |
| 3 | NESTED LOOPS | |
| 4 | NESTED LOOPS | |
| 5 | INDEX FULL SCAN | COUNTRY_C_ID_PK |
| 6 | TABLE ACCESS BY INDEX ROWID BATCHED| LOCATIONS |
| 7 | INDEX RANGE SCAN | LOC_COUNTRY_IX |
| 8 | TABLE ACCESS BY INDEX ROWID BATCHED | DEPARTMENTS |
| 9 | INDEX RANGE SCAN | DEPT_LOCATION_IX |
| 10 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX |
---------------------------------------------------------------------The execution plan is similar to the variant with the from_using_clause. So, from a performance point of view, this is a good option. However, I like the from_using_clause variant better because it’s clearer which table is updated and which tables are just used for query purposes.
SQL UPDATE RETURN Clause Enhancements
The returning_clause has been extended.
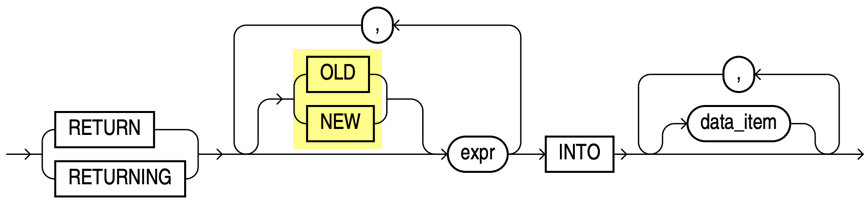
It’s now possible to explicitly return old and new values. The default depends on the operation. new in insert/update and old in delete statements. I do not see a lot of value for delete and insert statements besides maybe making the statements more explicit and therefore easier to read. However, for the update statement, this new feature can be useful.
Here’s a small SQL script showing the new returning clause in action for insert, update and delete.
set serveroutput on
drop table if exists t;
create table t (id integer, value integer);
declare
l_old_value t.value%type;
l_new_value t.value%type;
begin
dbms_random.seed(16);
insert into t (id, value)
values (1, dbms_random.value(low => 1, high => 100))
return new value into l_new_value;
dbms_output.put_line('Insert: new value ' || l_new_value);
update t
set value = value * 2
where id = 1
return old value, new value into l_old_value, l_new_value;
dbms_output.put_line('Update: old value ' || l_old_value || ', new value ' || l_new_value);
delete t
where id = 1
return old value into l_old_value;
dbms_output.put_line('Delete: old value ' || l_old_value);
end;
/Table T dropped.
Table T created.
Insert: new value 21
Update: old value 21, new value 42
Delete: old value 42
PL/SQL procedure successfully completed.DEFAULT ON NULL for UPDATE Statements
The column_definition clause in the create table statement has been extended.
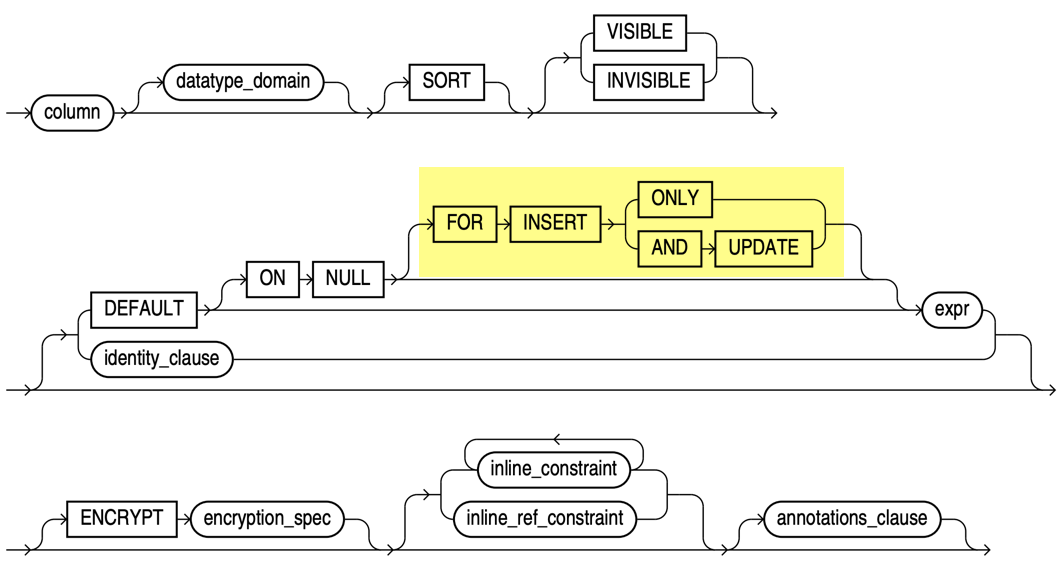
Finally, it’s possible to enforce the default on null expression also for update and merge statements.
The next SQL script demonstrates this.
drop table if exists t;
create table t (
id integer not null primary key,
value varchar2(10 char) default on null for insert and update 'my default'
);
insert into t(id, value)
values (1, 'value1'),
(2, null);
select * from t order by id;
update t set value = case id
when 1 then
null
when 2 then
'value2'
end;
select * from t order by id;
merge into t
using (values
(1, 'value3'),
(2, null),
(3, null)
) s (id, value)
on (t.id = s.id)
when matched then
update
set t.value = s.value
when not matched then
insert (t.id, t.value)
values (s.id, s.value);
select * from t order by id;Table T dropped.
Table T created.
2 rows inserted.
ID VALUE
---------- ----------
1 value1
2 my default
2 rows updated.
ID VALUE
---------- ----------
1 my default
2 value2
3 rows merged.
ID VALUE
---------- ----------
1 value3
2 my default
3 my defaultLock-Free Reservation
The new datatype_domain clause comes with a reservable keyword.
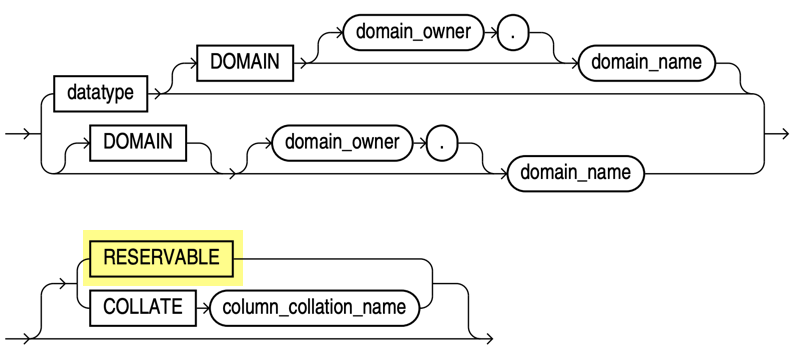
You can update reservable columns without locking a row. As a result, updating such a column is possible from multiple sessions in a transactional way. However, only numeric columns can be declared as reserveable.
Let’s make an example.
drop table if exists e;
create table e (
empno number(4,0) not null primary key,
ename varchar2(10) not null,
sal number(7,2) reservable not null
);
insert into e(empno, ename, sal)
values (7788, 'SCOTT', 3000),
(7739, 'KING', 5000);
commit;Table E dropped.
Table E created.
2 rows inserted.
Commit complete.After the setup, we run two database sessions in parallel.
update e
set sal = sal + 100
where empno = 7788;
select * from e;1 row updated.
EMPNO ENAME SAL
---------- ---------- ----------
7788 SCOTT 3000
7739 KING 5000update e
set sal = sal + 500
where empno = 7788;
select * from e;1 row updated.
EMPNO ENAME SAL
---------- ---------- ----------
7788 SCOTT 3000
7739 KING 5000We’ve updated the same record in two sessions. The transactions are pending and the changes are not yet visible in the target table. Let’s complete the pending transactions.
commit;
select * from e; Commit complete.
EMPNO ENAME SAL
---------- ---------- ----------
7788 SCOTT 3100
7739 KING 5000commit;
select * from e; Commit complete.
EMPNO ENAME SAL
---------- ---------- ----------
7788 SCOTT 3600
7739 KING 5000After committing, the changes are visible in the target table. The changes from both sessions have been applied. Concurrent updates of the same row without locking. Pure magic.
How is that possible? Quite simple. Behind the scenes, the Oracle Database creates a reservation journal table named SYS_RESERVJRNL_<object_id_of_table> for every table with a reservable column. This table stores the pending changes per session and applies them on commit. You can query this table, to better understand the process.
See the Database Development Guide for more information about lock-free reservations.
More New Features
More features are applicable in DML statements. For example, using sys_row_etag for optimistic locking or when working with JSON-relational duality views. The JSON-Relational Duality Developer’s Guide explains this new feature in detail.
For a complete list see Oracle Database New Features.
Outlook
For the next episode, the IslandSQL grammar will be extended to cover the PostgreSQL 16 grammar for the current statements in scope. This means all DML statements. I’m sure I will be able to show some interesting differences between the Oracle Database and PostgreSQL. Stay tuned.
1 Comment
[…] the last episode, we covered DML statements in SQL*Plus/SQLcl scripts for the Oracle Database 23c. The IslandSQL […]