


Introduction
In the last episode, we extended the expressions in the IslandSQL grammar to complete the lock table statement. The grammar now fully covers expressions, conditions and the select statement. In this episode, we will focus on optimizer hints and new features in the Oracle Database 23c that can be used in the select statement.
The full source code is available on GitHub, the binaries are on Maven Central and this VS Code extension uses the IslandSQL library to find text in DML statements and report syntax errors.
Token Channels
ANTLR uses the concept of channels which is based on the idea of radio frequencies. The lexer is responsible for identifying tokens and putting them on the right channel.
For most lexers, these two channels are enough:
DEFAULT_CHANNEL– all tokens that are relevant to the parserHIDDEN_CHANNEL– all other tokens
Here’s an example:
select█/*+ full(emp) */█*█from█emp█where█empno█=█7788█;
█/*+ full(emp) */█ █ █ █ █ █ █ █
select * from emp where empno = 7788 ;The first line contains the complete statement where a space token is represented as █ . The syntax highlighting helps to identify the 19 tokens. In the second line, you find all 10 hidden tokens – comments and whitespace. The noise, so to speak. And in the third line are the visible 9 tokens on the default channel.
This is similar to a noise-cancelling system. The parser only gets the tokens that are necessary to do its job.
Identifying Hints
In this blog post, I explained how you can distinguish hints from ordinary comments and highlight them in SQL Developer. Solving this problem was a bit more complicated because SQL Developer’s parse tree does not contain hints. Because hints are just special comments.
However, in the IslandSQL grammar, we want to define hints as part of a query_block. In other words, we want to make them visible.

In the Lexer?
Identifying hints in the lexer and putting them on the DEFAULT_CHANNEL sounds like a good solution. However, we do not want to handle comment tokens that look like a hint in every position in the parser. This would be a nightmare. To avoid that we could add a semantic predicate to consider only hint-style comments following the select keyword. Of course, we need to ignore whitespace and ordinary comments. Furthermore, we have to ensure that the select keyword is the start of a query_block and not used in another context such as a grant statement.
At that point, it becomes obvious that the lexer would be doing the job of the parser.
Better in the Parser!
We better use the lexer only to identify hint tokens and put them on the HIDDEN_CHANNEL:
ML_HINT: '/*+' .*? '*/' -> channel(HIDDEN);
ML_COMMENT: '/*' .*? '*/' -> channel(HIDDEN);
SL_HINT: '--+' ~[\r\n]* -> channel(HIDDEN);
SL_COMMENT: '--' ~[\r\n]* -> channel(HIDDEN);And then we define a semantic predicate in the parser:
queryBlock:
{unhideFirstHint();} K_SELECT hint?
queryBlockSetOperator?
selectList
(intoClause | bulkCollectIntoClause)? // in PL/SQL only
fromClause? // starting with Oracle Database 23c the from clause is optional
whereClause?
hierarchicalQueryClause?
groupByClause?
modelClause?
windowClause?
;That’s the call of the function unhideFirstHint();} on line 161. At that point, the parser is at the position of the token K_SELECT. Here’s the implementation in the base class of the generated parser:
public void unhideFirstHint() {
CommonTokenStream input = ((CommonTokenStream) this.getTokenStream());
List<Token> tokens = input.getHiddenTokensToRight(input.index());
if (tokens != null) {
for (Token token : tokens) {
if (token.getType() == IslandSqlLexer.ML_HINT || token.getType() == IslandSqlLexer.SL_HINT) {
((CommonToken) token).setChannel(Token.DEFAULT_CHANNEL);
return; // stop after first hint style comment
}
}
}
}We scan all hidden tokens to the right of the keyword select and set the first hint token to the DEFAULT_CHANNEL to make it visible to the parser.
Parse Tree
Let’s visualise the parse tree of the following query:
select -- A query_block can have only one comment
/* containing hints, and that comment must
follow the SELECT keyword. */
/*+ full(emp) */
--+ index(emp)
ename, sal -- select_list
from emp -- from_clause
where empno = 7788; -- where_clauseWe use ParseTreeUtil.dotParseTree to produce an output in DOT format and paste the result into the web UI of Edotor or any other Graphviz viewer to produce this result:

The leave nodes are sand-coloured rectangles. They represent the visible lexer tokens, the ones on the DEFAULT_CHANNEL. All other nodes are sky blue and elliptical. They represent a rule in the parser grammar.
I have changed the colour of the hint node to red so that you can spot it more easily. You see that it contains the /*+ full(emp) */ hint-style comment. All other comments are not visible in the parse tree. That’s what we wanted.
Here’s an alternative textual representation of the parse tree using ParseTreeUtil.printParseTree. It is better suited to represent larger parse trees. Furthermore, it contains also the symbol name of lexer tokens, for example K_SELECT or ML_HINT as you see in lines 7 and 9.
file
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
hint
ML_HINT:/*+ full(emp) */
selectList
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:ename
COMMA:,
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:sal
fromClause
K_FROM:from
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
sqlName
unquotedId
ID:emp
whereClause
K_WHERE:where
condition
expression:simpleComparisionCondition
expression:simpleExpressionName
sqlName
unquotedId
ID:empno
simpleComparisionOperator:eq
EQUALS:=
expression:simpleExpressionNumberLiteral
NUMBER:7788
sqlEnd
SEMI:;
<EOF>New Features in the Oracle Database 23c
The Oracle Database 23c comes with a lot of new features. See the new features guide for a complete list.
In the next chapters, we look at a few examples that are relevant when querying data. In other words, at some of the new features that are applicable in the select statement.
Graph Table Operator
You can use the new graph_table operator to query property graphs in the Oracle Database. It’s a table function similar to xml_table or json_table. A powerful addition to the converged database.
Setup
The SQL Language Reference 23 provides some good examples including a setup script.
The setup script is provided here for convenience. It’s a 1:1 copy from the SQL Language Reference with some minor additions and modifications.
The most important change is that business keys are used in the insert statements to retrieve the associated surrogate keys. As a result, it’s easier to add test data.
-- drop existing property graph including data
drop property graph if exists students_graph;
drop table if exists friendships;
drop table if exists students;
drop table if exists persons;
drop table if exists university;
-- create tables, insert data and create property graph
create table university (
id number generated always as identity (start with 1 increment by 1) not null,
name varchar2(10) not null,
constraint u_pk primary key (id),
constraint u_uk unique (name)
);
insert into university (name) values ('ABC'), ('XYZ');
create table persons (
person_id number generated always as identity (start with 1 increment by 1) not null,
name varchar2(10) not null,
birthdate date not null,
height float not null,
person_data json not null,
constraint person_pk primary key (person_id),
constraint person_uk unique (name)
);
insert into persons (name, height, birthdate, person_data)
values ('John', 1.80, date '1963-06-13', '{"department":"IT","role":"Software Developer"}'),
('Mary', 1.65, date '1982-09-25', '{"department":"HR","role":"HR Manager"}'),
('Bob', 1.75, date '1966-03-11', '{"department":"IT","role":"Technical Consultant"}'),
('Alice', 1.70, date '1987-02-01', '{"department":"HR","role":"HR Assistant"}');
create table students (
s_id number generated always as identity (start with 1 increment by 1) not null,
s_univ_id number not null,
s_person_id number not null,
subject varchar2(10) not null,
constraint stud_pk primary key (s_id),
constraint stud_uk unique (s_univ_id, s_person_id),
constraint stud_fk_person foreign key (s_person_id) references persons(person_id),
constraint stud_fk_univ foreign key (s_univ_id) references university(id)
);
insert into students(s_univ_id, s_person_id, subject)
select u.id, p.person_id, d.subject
from (values
(1, 'ABC', 'John', 'Arts'),
(2, 'ABC', 'Bob', 'Music'),
(3, 'XYZ', 'Mary', 'Math'),
(4, 'XYZ', 'Alice', 'Science')
) as d (seq, uni_name, pers_name, subject)
join university u
on u.name = d.uni_name
join persons p
on p.name = d.pers_name
order by d.seq;
create table friendships (
friendship_id number generated always as identity (start with 1 increment by 1) not null,
person_a number not null,
person_b number not null,
meeting_date date not null,
constraint fk_person_a_id foreign key (person_a) references persons(person_id),
constraint fk_person_b_id foreign key (person_b) references persons(person_id),
constraint fs_pk primary key (friendship_id),
constraint fs_uk unique (person_a, person_b)
);
insert into friendships (person_a, person_b, meeting_date)
select a.person_id, b.person_id, d.meeting_date
from (values
(1, 'John', 'Bob', date '2000-09-01'),
(2, 'Mary', 'Alice', date '2000-09-19'),
(3, 'Mary', 'John', date '2000-09-19'),
(4, 'Bob', 'Mary', date '2001-07-10')
) as d (seq, name_a, name_b, meeting_date)
join persons a
on a.name = d.name_a
join persons b
on b.name = d.name_b
order by d.seq;
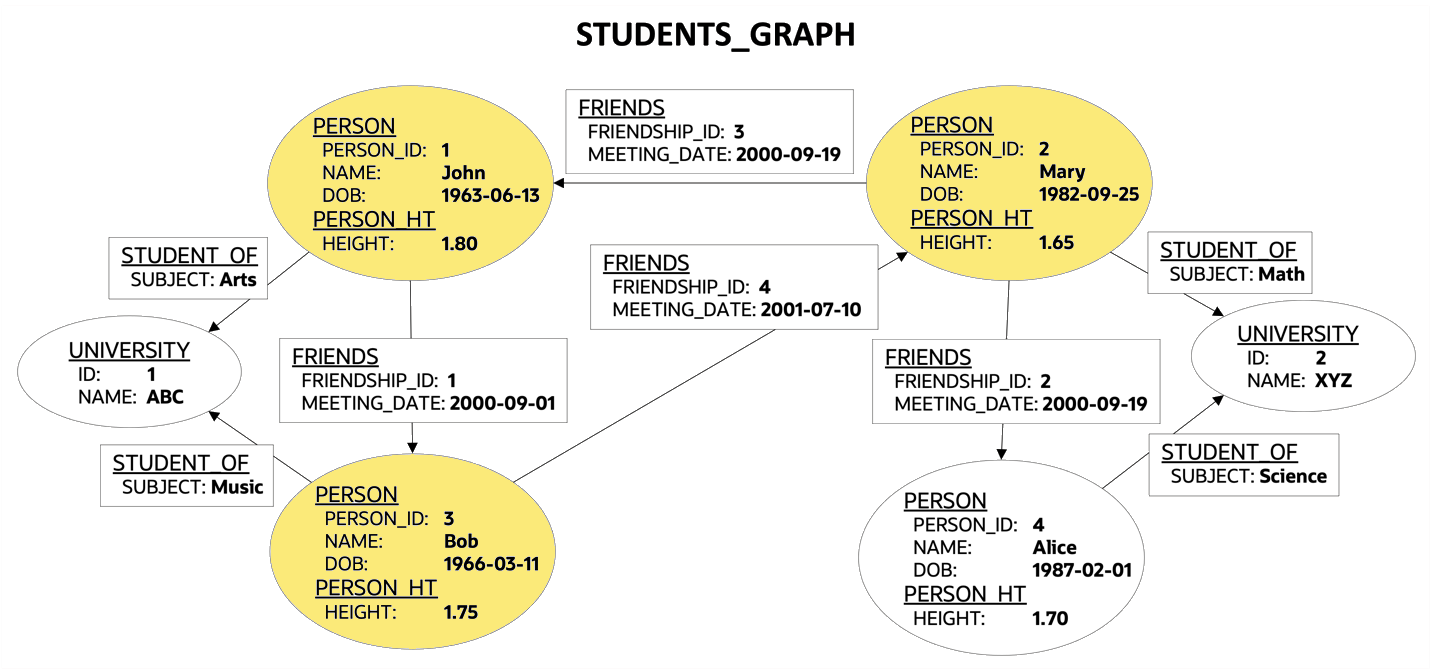
create property graph students_graph
vertex tables (
persons key (person_id)
label person
properties (person_id, name, birthdate as dob)
label person_ht
properties (height),
university key (id)
)
edge tables (
friendships as friends
key (friendship_id)
source key (person_a) references persons(person_id)
destination key (person_b) references persons(person_id)
properties (friendship_id, meeting_date),
students as student_of
source key (s_person_id) references persons(person_id)
destination key (s_univ_id) references university(id)
properties (subject)
);The example property graph looks like this:
Query
select a_name, b_name, c_name
from graph_table (
students_graph
match
(a is person)
-[is friends]-> -- a is friend of b
(b is person)
-[is friends]-> -- b is friend of c
(c is person)
-[is friends]-> -- c is friend of a (cyclic path)
(a)
where
a.name = 'Mary' -- start of cyclic path with 3 nodes
columns (
a.name as a_name,
b.name as b_name,
c.name as c_name
)
) g;A_NAME B_NAME C_NAME
---------- ---------- ----------
Mary John Bob Edges and Directions
An edge has a source and a destination vertex. According to the model, Mary is a friend of John and this means that John is also a friend of Mary. When we change the direction of the edges in the query from -[is friends]-> to <-[is friends]- the query result changes to:
A_NAME B_NAME C_NAME
---------- ---------- ----------
Mary Bob John We’ve got now the clockwise result of the cyclic path starting with Mary (see the highlighted person vertices in the STUDENTS_GRAPH figure above).
Since there is only one type of edge between the vertices of the type persons we get the same result by using just <-[]- or even <-.
To ignore the direction of a friendship we can use <-[is friends]-> or -[is friends]- or <-[]-> or -[]- or <-> or just - to produce this result:
A_NAME B_NAME C_NAME
---------- ---------- ----------
Mary Bob John
Mary John Bob IMO this arrow-like syntax is intuitive and makes a graph_table query relatively easy to read and write.
file
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
selectList
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:a_name
COMMA:,
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:b_name
COMMA:,
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:c_name
fromClause
K_FROM:from
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
expression:specialFunctionExpressionParent
specialFunctionExpression
graphTable
K_GRAPH_TABLE:graph_table
LPAR:(
sqlName
unquotedId
ID:students_graph
K_MATCH:match
pathTerm
pathTerm
pathTerm
pathTerm
pathTerm
pathTerm
pathTerm
pathFactor
pathPrimary
elementPattern
vertexPattern
LPAR:(
elementPatternFiller
sqlName
unquotedId
keywordAsId
K_A:a
K_IS:is
labelExpression
sqlName
unquotedId
ID:person
RPAR:)
pathFactor
pathPrimary
elementPattern
edgePattern
fullEdgePattern
fullEdgePointingRight
MINUS:-
LSQB:[
elementPatternFiller
K_IS:is
labelExpression
sqlName
unquotedId
ID:friends
RSQB:]
MINUS:-
GT:>
pathFactor
pathPrimary
elementPattern
vertexPattern
LPAR:(
elementPatternFiller
sqlName
unquotedId
ID:b
K_IS:is
labelExpression
sqlName
unquotedId
ID:person
RPAR:)
pathFactor
pathPrimary
elementPattern
edgePattern
fullEdgePattern
fullEdgePointingRight
MINUS:-
LSQB:[
elementPatternFiller
K_IS:is
labelExpression
sqlName
unquotedId
ID:friends
RSQB:]
MINUS:-
GT:>
pathFactor
pathPrimary
elementPattern
vertexPattern
LPAR:(
elementPatternFiller
sqlName
unquotedId
ID:c
K_IS:is
labelExpression
sqlName
unquotedId
ID:person
RPAR:)
pathFactor
pathPrimary
elementPattern
edgePattern
fullEdgePattern
fullEdgePointingRight
MINUS:-
LSQB:[
elementPatternFiller
K_IS:is
labelExpression
sqlName
unquotedId
ID:friends
RSQB:]
MINUS:-
GT:>
pathFactor
pathPrimary
elementPattern
vertexPattern
LPAR:(
elementPatternFiller
sqlName
unquotedId
keywordAsId
K_A:a
RPAR:)
K_WHERE:where
condition
expression:simpleComparisionCondition
expression:binaryExpression
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_A:a
PERIOD:.
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_NAME:name
simpleComparisionOperator:eq
EQUALS:=
expression:simpleExpressionStringLiteral
STRING:'Mary'
K_COLUMNS:columns
LPAR:(
graphTableColumnDefinition
expression:binaryExpression
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_A:a
PERIOD:.
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_NAME:name
K_AS:as
sqlName
unquotedId
ID:a_name
COMMA:,
graphTableColumnDefinition
expression:binaryExpression
expression:simpleExpressionName
sqlName
unquotedId
ID:b
PERIOD:.
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_NAME:name
K_AS:as
sqlName
unquotedId
ID:b_name
COMMA:,
graphTableColumnDefinition
expression:binaryExpression
expression:simpleExpressionName
sqlName
unquotedId
ID:c
PERIOD:.
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_NAME:name
K_AS:as
sqlName
unquotedId
ID:c_name
RPAR:)
RPAR:)
sqlName
unquotedId
ID:g
sqlEnd
SEMI:;
<EOF>
Table Value Constructor
Instead of reading rows from a table/view, you can produce rows on the fly using the new values_clause. This makes it possible to produce rows without writing a query_block for each row and using union all as a kind of row separator.
column english format a7
column german format a7
with
eng (digit, english) as (values
(1, 'one'),
(2, 'two')
)
select digit, english, german
from eng e
natural full join (values
(2, 'zwei'),
(3, 'drei')
) as g (digit, german)
order by digit;
/ DIGIT ENGLISH GERMAN
---------- ------- -------
1 one
2 two zwei
3 drei file
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
withClause
K_WITH:with
factoringClause
subqueryFactoringClause
sqlName
unquotedId
ID:eng
LPAR:(
sqlName
unquotedId
ID:digit
COMMA:,
sqlName
unquotedId
ID:english
RPAR:)
K_AS:as
valuesClause
LPAR:(
K_VALUES:values
valuesRow
LPAR:(
expression:simpleExpressionNumberLiteral
NUMBER:1
COMMA:,
expression:simpleExpressionStringLiteral
STRING:'one'
RPAR:)
COMMA:,
valuesRow
LPAR:(
expression:simpleExpressionNumberLiteral
NUMBER:2
COMMA:,
expression:simpleExpressionStringLiteral
STRING:'two'
RPAR:)
RPAR:)
queryBlock
K_SELECT:select
selectList
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:digit
COMMA:,
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:english
COMMA:,
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:german
fromClause
K_FROM:from
fromItem:joinClause
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
sqlName
unquotedId
ID:eng
sqlName
unquotedId
ID:e
joinVariant
outerJoinClause
K_NATURAL:natural
outerJoinType
K_FULL:full
K_JOIN:join
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
valuesClause
LPAR:(
K_VALUES:values
valuesRow
LPAR:(
expression:simpleExpressionNumberLiteral
NUMBER:2
COMMA:,
expression:simpleExpressionStringLiteral
STRING:'zwei'
RPAR:)
COMMA:,
valuesRow
LPAR:(
expression:simpleExpressionNumberLiteral
NUMBER:3
COMMA:,
expression:simpleExpressionStringLiteral
STRING:'drei'
RPAR:)
RPAR:)
K_AS:as
sqlName
unquotedId
ID:g
LPAR:(
sqlName
unquotedId
ID:digit
COMMA:,
sqlName
unquotedId
ID:german
RPAR:)
orderByClause
K_ORDER:order
K_BY:by
orderByItem
expression:simpleExpressionName
sqlName
unquotedId
ID:digit
sqlEnd
SEMI:;
<EOF>
JSON_ARRAY Constructor by Query
The function json_array has got a new JSON_ARRAY_query_content clause. This clause simplifies the creation of JSON documents, similar to SQL/XML. If you use the abbreviated syntax for json_array and json_object it feels like writing JSON documents with embedded SQL.
column result format a90
select json [
select json {
'ename': ename,
'sal': sal,
'comm': comm absent on null
}
from emp
where sal >= 3000
returning json
] as result;RESULT
------------------------------------------------------------------------------------------
[{"ename":"SCOTT","sal":3000},{"ename":"KING","sal":5000},{"ename":"FORD","sal":3000}] file
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
selectList
selectItem
expression:specialFunctionExpressionParent
specialFunctionExpression
jsonArray
K_JSON:json
LSQB:[
jsonArrayContent
jsonArrayQueryContent
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
selectList
selectItem
expression:specialFunctionExpressionParent
specialFunctionExpression
jsonObject
K_JSON:json
LCUB:{
jsonObjectContent
entry
regularEntry
expression:simpleExpressionStringLiteral
STRING:'ename'
COLON::
expression:simpleExpressionName
sqlName
unquotedId
ID:ename
COMMA:,
entry
regularEntry
expression:simpleExpressionStringLiteral
STRING:'sal'
COLON::
expression:simpleExpressionName
sqlName
unquotedId
ID:sal
COMMA:,
entry
regularEntry
expression:simpleExpressionStringLiteral
STRING:'comm'
COLON::
expression:simpleExpressionName
sqlName
unquotedId
ID:comm
jsonOnNullClause
K_ABSENT:absent
K_ON:on
K_NULL:null
RCUB:}
fromClause
K_FROM:from
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
sqlName
unquotedId
ID:emp
whereClause
K_WHERE:where
condition
expression:simpleComparisionCondition
expression:simpleExpressionName
sqlName
unquotedId
ID:sal
simpleComparisionOperator:ge
GT:>
EQUALS:=
expression:simpleExpressionNumberLiteral
NUMBER:3000
jsonReturningClause
K_RETURNING:returning
K_JSON:json
RSQB:]
K_AS:as
sqlName
unquotedId
ID:result
sqlEnd
SEMI:;
<EOF>
SQL Boolean Data Type
Where can the new Boolean data type be used in the select statement? In conversion functions, for example.
column dump_yes_value format a20
select cast('yes' as boolean) as yes_value,
xmlcast(xmltype('<x>no</x>') as boolean) as no_value,
validate_conversion('maybe' as boolean) as is_maybe_boolean,
dump(cast('yes' as boolean)) as dump_yes_value;YES_VALUE NO_VALUE IS_MAYBE_BOOLEAN DUMP_YES_VALUE
----------- ----------- ---------------- --------------------
TRUE FALSE 0 Typ=252 Len=1: 1file
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
selectList
selectItem
expression:specialFunctionExpressionParent
specialFunctionExpression
cast
K_CAST:cast
LPAR:(
expression:simpleExpressionStringLiteral
STRING:'yes'
K_AS:as
dataType
oracleBuiltInDatatype
booleanDatatype
K_BOOLEAN:boolean
RPAR:)
K_AS:as
sqlName
unquotedId
ID:yes_value
COMMA:,
selectItem
expression:specialFunctionExpressionParent
specialFunctionExpression
xmlcast
K_XMLCAST:xmlcast
LPAR:(
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_XMLTYPE:xmltype
LPAR:(
functionParameter
condition
expression:simpleExpressionStringLiteral
STRING:'<x>no</x>'
RPAR:)
K_AS:as
dataType
oracleBuiltInDatatype
booleanDatatype
K_BOOLEAN:boolean
RPAR:)
K_AS:as
sqlName
unquotedId
ID:no_value
COMMA:,
selectItem
expression:specialFunctionExpressionParent
specialFunctionExpression
validateConversion
K_VALIDATE_CONVERSION:validate_conversion
LPAR:(
expression:simpleExpressionStringLiteral
STRING:'maybe'
K_AS:as
dataType
oracleBuiltInDatatype
booleanDatatype
K_BOOLEAN:boolean
RPAR:)
K_AS:as
sqlName
unquotedId
ID:is_maybe_boolean
COMMA:,
selectItem
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
ID:dump
LPAR:(
functionParameter
condition
expression:specialFunctionExpressionParent
specialFunctionExpression
cast
K_CAST:cast
LPAR:(
expression:simpleExpressionStringLiteral
STRING:'yes'
K_AS:as
dataType
oracleBuiltInDatatype
booleanDatatype
K_BOOLEAN:boolean
RPAR:)
RPAR:)
K_AS:as
sqlName
unquotedId
ID:dump_yes_value
sqlEnd
SEMI:;
<EOF>
Boolean Expressions
The impact of Boolean expressions is huge. A condition becomes an expression that returns a Boolean expression. Consequently, conditions can be used wherever expressions are permitted.
with
function f(p in boolean) return boolean is
begin
return p;
end;
select (select count(*) from emp) = 14 and (select count(*) from dept) = 4 as is_complete,
f(1>0) is true as is_true,
cast(null as boolean) is not null as is_not_null;
/IS_COMPLETE IS_TRUE IS_NOT_NULL
----------- ----------- -----------
TRUE TRUE FALSEfile
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
withClause
K_WITH:with
plsqlDeclarations
functionDeclaration
K_FUNCTION:function
plsqlCode
ID:f
LPAR:(
ID:p
K_IN:in
K_BOOLEAN:boolean
RPAR:)
K_RETURN:return
K_BOOLEAN:boolean
K_IS:is
ID:begin
K_RETURN:return
ID:p
SEMI:;
K_END:end
SEMI:;
queryBlock
K_SELECT:select
selectList
selectItem
expression:simpleComparisionCondition
expression:simpleComparisionCondition
expression:scalarSubqueryExpression
LPAR:(
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
selectList
selectItem
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_COUNT:count
LPAR:(
functionParameter
condition
expression:allColumnWildcardExpression
AST:*
RPAR:)
fromClause
K_FROM:from
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
sqlName
unquotedId
ID:emp
RPAR:)
simpleComparisionOperator:eq
EQUALS:=
expression:logicalCondition
expression:simpleExpressionNumberLiteral
NUMBER:14
K_AND:and
expression:scalarSubqueryExpression
LPAR:(
subquery:subqueryQueryBlock
queryBlock
K_SELECT:select
selectList
selectItem
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_COUNT:count
LPAR:(
functionParameter
condition
expression:allColumnWildcardExpression
AST:*
RPAR:)
fromClause
K_FROM:from
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
sqlName
unquotedId
ID:dept
RPAR:)
simpleComparisionOperator:eq
EQUALS:=
expression:simpleExpressionNumberLiteral
NUMBER:4
K_AS:as
sqlName
unquotedId
ID:is_complete
COMMA:,
selectItem
expression:isTrueCondition
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
ID:f
LPAR:(
functionParameter
condition
expression:simpleComparisionCondition
expression:simpleExpressionNumberLiteral
NUMBER:1
simpleComparisionOperator:gt
GT:>
expression:simpleExpressionNumberLiteral
NUMBER:0
RPAR:)
K_IS:is
K_TRUE:true
K_AS:as
sqlName
unquotedId
ID:is_true
COMMA:,
selectItem
expression:isNullCondition
expression:specialFunctionExpressionParent
specialFunctionExpression
cast
K_CAST:cast
LPAR:(
expression:simpleExpressionName
sqlName
unquotedId
keywordAsId
K_NULL:null
K_AS:as
dataType
oracleBuiltInDatatype
booleanDatatype
K_BOOLEAN:boolean
RPAR:)
K_IS:is
K_NOT:not
K_NULL:null
K_AS:as
sqlName
unquotedId
ID:is_not_null
sqlEnd
SEMI:;
SOL:/
<EOF>
JSON Schema
There is an extended is_JSON_condition that makes it possible to validate a JSON document against a JSON schema.
column j format a20
with
t (j) as (values
(json('["a", "b"]')), -- JSON array
(json('{"a": "a", "b": "b"}')), -- JSON object without id property
(json('{"id": 42}')), -- JSON object with numeric id property
(json('{"id": "42"}')) -- JSON object with string id property
)
select j,
j is json validate '
{
"type": "object",
"properties": {
"id": { "type": "number" }
}
}' as is_valid
from t;J IS_VALID
-------------------- -----------
["a","b"] FALSE
{"a":"a","b":"b"} TRUE
{"id":42} TRUE
{"id":"42"} FALSEfile
dmlStatement
selectStatement
select
subquery:subqueryQueryBlock
withClause
K_WITH:with
factoringClause
subqueryFactoringClause
sqlName
unquotedId
ID:t
LPAR:(
sqlName
unquotedId
ID:j
RPAR:)
K_AS:as
valuesClause
LPAR:(
K_VALUES:values
valuesRow
LPAR:(
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_JSON:json
LPAR:(
functionParameter
condition
expression:simpleExpressionStringLiteral
STRING:'["a", "b"]'
RPAR:)
RPAR:)
COMMA:,
valuesRow
LPAR:(
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_JSON:json
LPAR:(
functionParameter
condition
expression:simpleExpressionStringLiteral
STRING:'{"a": "a", "b": "b"}'
RPAR:)
RPAR:)
COMMA:,
valuesRow
LPAR:(
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_JSON:json
LPAR:(
functionParameter
condition
expression:simpleExpressionStringLiteral
STRING:'{"id": 42}'
RPAR:)
RPAR:)
COMMA:,
valuesRow
LPAR:(
expression:functionExpressionParent
functionExpression
sqlName
unquotedId
keywordAsId
K_JSON:json
LPAR:(
functionParameter
condition
expression:simpleExpressionStringLiteral
STRING:'{"id": "42"}'
RPAR:)
RPAR:)
RPAR:)
queryBlock
K_SELECT:select
selectList
selectItem
expression:simpleExpressionName
sqlName
unquotedId
ID:j
COMMA:,
selectItem
expression:isJsonCondition
expression:simpleExpressionName
sqlName
unquotedId
ID:j
K_IS:is
K_JSON:json
jsonConditionOption:jsonConditionOptionValidate
K_VALIDATE:validate
expression:simpleExpressionStringLiteral
STRING:'\n {\n "type": "object",\n "properties": {\n "id": { "type": "number" }\n }\n }'
K_AS:as
sqlName
unquotedId
ID:is_valid
fromClause
K_FROM:from
fromItem:tableReferenceFromItem
tableReference
queryTableExpression
sqlName
unquotedId
ID:t
sqlEnd
SEMI:;
<EOF>
What Else?
There are more new features in the Oracle Database 23c that you can use in the select statement, such as:
- The data quality operators
fuzzy_matchandphonic_encode - Dangling predicates in case expressions and case statements within
plsql_declarations - New functions related to the Boolean data type:
boolean_and_agg,every,boolean_or_aggandto_boolean - New functions related to domains:
domain_check,domain_check_type,domain_display,domain_nameanddomain_order - New
JSON_passing_clauseandtypeclause injson_queryandjson_value - New
on nullandon errorclauses injson_scalar - New
orderedclause injson_serialize - New
typeclause injson_tableandjson_transform - New operations
sort,nested_path,case,copy,intersect,merge,minus,prependandunioninjson_transform
We can also assume that more features will be added with future release updates. The AI vector search, for example, should be available with 23.4 later this year.
Outlook
The plan for IslandSQL is still the same as outlined in the previous episode. So we should cover the remaining DML statements (call, delete, explain plan, insert, merge and update) in the next episode.
1 Comment
[…] In this episode, we will focus on new features in the Oracle Database 23c that can be used in insert, update, delete and merge statements. For the select statement see the last episode. […]