


Introduction
Autonomous transactions became available in the Oracle Database 8i Release 1 (8.1.5). 25 years ago. Before then the feature was used only internally, for example, when requesting a new value from a sequence. I mean, if Oracle is using autonomous transactions internally and they’ve made them public, then the usage can hardly be bad, right? – Wrong.
“The legitimate real-world use of autonomous transactions is exceedingly rare. If you find them to be a feature you are using constantly, you’ll want to take a long, hard look at why.”
— Tom Kyte
In this blog post, I’d like to discuss some of the side effects of autonomous transactions.
Example in X Poll
Here’s the screenshot of a poll result on X (Twitter).
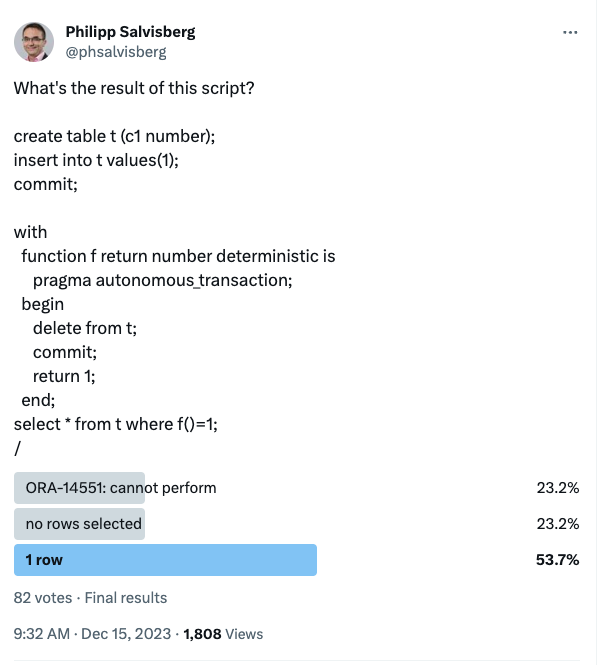
You can run this SQL script using a common SQL client connected to an Oracle Database 12c instance or higher.
I’ve run this script against the following Oracle database versions with the same result: 23.3, 21.8, 21.3, 19.22, 19.21, 19.19, 19.17, 18.4, 12.2 and 12.1. It should therefore also work in your environment using SQL*Plus, SQLcl or SQL Developer. Simply drop the possibly existing table t beforehand.
create table t (c1 number);
insert into t values(1);
commit;
with
function f return number deterministic is
pragma autonomous_transaction;
begin
delete from t;
commit;
return 1;
end;
select * from t where f() = 1;
/ C1
----------
1The query result shows the row inserted on line 2. So the majority of respondents were right.
Just to be clear: This result is expected. It is not a bug. The reason why the query returns one row is the statement-level read consistency of the Oracle database. We see the data as it was at the start of the query. The autonomous transaction that deletes all rows is completed (committed) after the query is started. As a result, changes made by the autonomous transaction are not visible in the main transaction.
When Do We Get an ORA-14551?
I like the features introduced in 23c, such as the IF [NOT] EXISTS syntax support. That’s why I’m using the 23c syntax in this blog post from now on. However, it should not be too difficult to adapt the code for older versions.
The next script looks very similar to the first one. The difference is that the function f does not contain the pragma autonomous_transaction anymore. The default, so to speak. And this leads to a different result.
drop table if exists t;
create table t (c1 number);
insert into t values(1);
commit;
with
function f return number deterministic is
begin
delete from t;
commit;
return 1;
end;
select * from t where f()=1;
/Error starting at line : 6 in command -
with
function f return number deterministic is
begin
delete from t;
commit;
return 1;
end;
select * from t where f()=1
Error at Command Line : 13 Column : 15
Error report -
SQL Error: ORA-14551: cannot perform a DML operation inside a query
ORA-06512: at line 3
ORA-06512: at line 7
14551. 00000 - "cannot perform a DML operation inside a query "
*Cause: DML operation like insert, update, delete or select-for-update
cannot be performed inside a query or under a PDML slave.
*Action: Ensure that the offending DML operation is not performed or
use an autonomous transaction to perform the DML operation within
the query or PDML slave.
More Details :
https://docs.oracle.com/error-help/db/ora-14551/
https://docs.oracle.com/error-help/db/ora-06512/The error message, the cause and the action are good. You get even the information that you can work around the problem by using an autonomous transaction.
What is missing, however, is the information on why performing a DML operation within a query is a bad thing. Maybe it’s too obvious. Who would expect a query to change data? – Probably nobody. It therefore makes sense to prohibit DML in queries by default.
When Do We Get No Rows?
Add Logging
Let’s add some logging information to the query to better understand what is being executed and when.
drop table if exists t;
create table t (c1 number);
insert into t values (1), (2);
commit;
drop table if exists l;
create table l (
id integer generated always as identity primary key,
text varchar2(50 char)
);
column logit format a20
with
procedure logit (in_text in varchar2) is
pragma autonomous_transaction;
begin
insert into l(text) values(in_text);
commit;
end;
function logit (in_text in varchar2) return varchar2 is
begin
logit(in_text);
return in_text;
end;
function f return number deterministic is
pragma autonomous_transaction;
begin
logit('in function f');
delete from t;
commit;
return 1;
end;
select c1, logit('in select_list') as logit
from t
where f() = 1 and logit('in where_clause') is not null;
/
select * from l order by id; C1 LOGIT
---------- --------------------
1 in select_list
2 in select_list
ID TEXT
---------- --------------------------------------------------
1 in where_clause
2 in function f
3 in select_list
4 in select_list We have inserted an additional row into the table t to understand better how often a function is called. A logit call produces a row in the new table l.
The query on the table t returns now two rows. That’s expected due to statement-level read consistency.
The query result on the table l reveals the order in which the logit calls were evaluated by the Oracle Database.
So far so good.
DML Restart
The Oracle Database can restart any DML statement. Automatically or intentionally via our code, for example in exception handlers. A restart also implies a rollback. The scope of a rollback is the current transaction. Changes that are made outside the current transaction, such as writing to a file, calling a REST service or executing code in an autonomous transaction, remain unaffected by a rollback. This means that the application is responsible for reversing changes made outside the current transaction.
Let’s force a DML restart. Franck Pachot provided the simplest solution in this post on X that works in a single database session. The script looks the same as before, we only added a for update clause on line 35.
drop table if exists t purge;
create table t (c1 number);
insert into t values (1), (2);
commit;
drop table if exists l purge;
create table l (
id integer generated always as identity primary key,
text varchar2(50 char)
);
column logit format a20
with
procedure logit (in_text in varchar2) is
pragma autonomous_transaction;
begin
insert into l(text) values(in_text);
commit;
end;
function logit (in_text in varchar2) return varchar2 is
begin
logit(in_text);
return in_text;
end;
function f return number deterministic is
pragma autonomous_transaction;
begin
logit('in function f');
delete from t;
commit;
return 1;
end;
select c1, logit('in select_list') as logit
from t
where f() = 1 and logit('in where_clause') is not null
for update;
/
select * from l order by id;no rows selected
ID TEXT
---------- --------------------------------------------------
1 in where_clause
2 in function f
3 in where_clause The query on the table t now returns no rows. The log contains two rows with the text “in where clause”. The second one is a clear indication of a DML restart.
Again, this is not a bug in the Oracle Database. It’s a bug in the application code.
But why is the function f just called once? – Because the function is declared as deterministic (a false claim, BTW, but a necessary evil to avoid an ORA-600 due to recursive restarts). The Oracle database already knows the result of the function call where no parameters are passed. As a result, there is no need to re-evaluate it.
And why was the statement restarted? – Because the Oracle Database detected that the rows to be locked have been changed. Locking outdated versions of a row is not possible and it would not make any sense. So the database is left with two options. Either throw an error or restart the statement. “Let’s try again” is a solution approach we often use when something doesn’t work on the first attempt. This also works for the Oracle Database.
DML Restart – Using Update Instead Of Delete
Although what I wrote before sounds reasonable, I’d still like to verify it.
So, let’s change the previous script slightly and replace the delete with a update statement on line 28.
drop table if exists t;
create table t (c1 number);
insert into t values (1), (2);
commit;
drop table if exists l;
create table l (
id integer generated always as identity primary key,
text varchar2(50 char)
);
column logit format a20
with
procedure logit (in_text in varchar2) is
pragma autonomous_transaction;
begin
insert into l(text) values(in_text);
commit;
end;
function logit (in_text in varchar2) return varchar2 is
begin
logit(in_text);
return in_text;
end;
function f return number deterministic is
pragma autonomous_transaction;
begin
logit('in function f');
update t set c1 = c1 + 1;
commit;
return 1;
end;
select c1, logit('in select_list') as logit
from t
where f() = 1 and logit('in where_clause') is not null
for update;
/
select * from l order by id; C1 LOGIT
---------- --------------------
2 in select_list
3 in select_list
ID TEXT
---------- --------------------------------------------------
1 in where_clause
2 in function f
3 in where_clause
4 in select_list
5 in select_list See, the query on the table t returns now the two updated rows. The effect of the restarted statement.
Real-Life Use Case
This blog post was inspired by a real-life use case. The original question was how to call a package procedure at the end of a process from a security and observability tool when this tool can run queries only.
Here’s the screenshot of an X post by my colleague Stefan Oehrli that demonstrates a possible solution approach. Just replace count(*) with a couple of columns from the table unified_audit_trail to make it realistic.
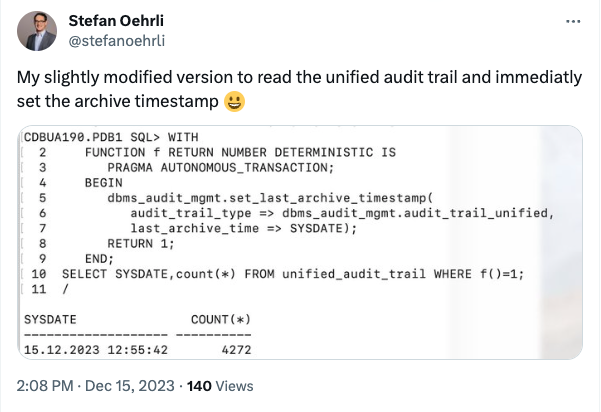
While this technically “solves” the original requirement it comes with a couple of issues, for example:
- What happens if the query succeeds but the result cannot be stored successfully in the target database? – Data loss, since the autonomous transaction succeeded and the data is not provided with the next access.
- What happens when the query crashes? – Again data loss as in the previous case. It does not matter how many rows have been read.
- How can we reload some previously processed data? – This might not be possible with this approach, which is bad because it could solve the previous two issues.
The problem with this approach is that this easy implementation comes at the price of possible data loss. That’s fine as long as the stakeholders know this in advance and accept the risk. However, I can imagine that this is not good enough. Especially when dealing with security-relevant data, we should strive for the best possible approach and not be satisfied with the easiest solution to implement.
Alternatives to Autonomous Transactions
Years ago I was a fan of autonomous transactions. They allow me to persist data in logging tables even if the main transaction is not committed. That’s a great feature. However, over the years I’ve seen some abuse of autonomous transactions that changed my mind. I still like to use autonomous transactions for debugging purposes. But that’s it. Using them for something else is most probably a bug in the application code.
So what are the alternatives?
1. Make the Right Application Responsible for Data Consistency
Take a step back and think about who should be in charge of a certain process. The “real use case” mentioned above for example. I believe that the security and observability tool is responsible for the data it reads, processes and stores in its data store. This means that this tool should have mechanisms in place to remember the last processed log entry per source with the corresponding restart points and procedures. Moving this responsibility to the source for a part of it like “remembering the last processed log entry” is just plain wrong and leads to the issues outlined above.
Shifting process responsibility to the right place makes the use of autonomous transactions most probably superfluous.
2. Advanced Queues
Advanced Queues are transactional (enqueue and dequeue). It’s an excellent way to postpone certain parts of a transaction that you would like to be transactional, but which are not. For example, sending an e-mail, calling a REST service or calling a functionality that contains TCL statements. You can configure how to deal with failures such as the number of retries, delay time, etc. This leads to a more transactional-like behaviour than using autonomous transactions.
3. One-time Jobs
Jobs are similar to queue messages. You create them as part of the transaction. They might be the easier solution because the dequeue process is the job system itself.
Conclusion
Your application should contain at most one PL/SQL unit with a pragma autonomous_transaction. The one for storing logging/debugging messages as part of your instrumentation strategy.
Autonomous transactions may seem appealing for quickly solving certain problems or requirements. However, they come with the risk of data inconsistencies.
Even when analyzing logging/debugging data generated by autonomous transactions, we need to be aware that an entry does not mean that an action has taken place, as it could have been undone via a rollback.