

Introduction
In the last episode, we build the initial version of IslandSQL. An Island grammar for SQL scripts covering select statements. In this blog post, we extend the grammar to handle the remaining DML statements.
The full source code is available on GitHub and the binaries on Maven Central.
Lexer Changes
The lexer grammar contains a new fragment COMMENT_OR_WS on line 98. We use this fragment in all DML lexer rules after the starting keywords. Why? Because we can use comments beside whitespace after a keyword as in with/*comment*/function e_count.... The previous lexer version required a whitespace after the with keyword for select statements with a plsql_declarations clause.
I also merged the former PLSQL_DECLARATION rule into the SELECT rule. Mainly to have a single lexer rule for all DML statements. It’s more consistent and easier to understand IMO.
lexer grammar IslandSqlLexer;
options {
superClass=IslandSqlLexerBase;
caseInsensitive = true;
}
/*----------------------------------------------------------------------------*/
// Comments and alike to be ignored
/*----------------------------------------------------------------------------*/
ML_COMMENT: '/*' .*? '*/' -> channel(HIDDEN);
SL_COMMENT: '--' .*? (EOF|SINGLE_NL) -> channel(HIDDEN);
REMARK_COMMAND:
{isBeginOfCommand()}? 'rem' ('a' ('r' 'k'?)?)?
(WS SQLPLUS_TEXT*)? SQLPLUS_END -> channel(HIDDEN)
;
PROMPT_COMMAND:
{isBeginOfCommand()}? 'pro' ('m' ('p' 't'?)?)?
(WS SQLPLUS_TEXT*)? SQLPLUS_END -> channel(HIDDEN)
;
STRING:
'n'?
(
(['] .*? ['])+
| ('q' ['] '[' .*? ']' ['])
| ('q' ['] '(' .*? ')' ['])
| ('q' ['] '{' .*? '}' ['])
| ('q' ['] '<' .*? '>' ['])
| ('q' ['] . {saveQuoteDelimiter1()}? .+? . ['] {checkQuoteDelimiter2()}?)
) -> channel(HIDDEN)
;
CONDITIONAL_COMPILATION_DIRECTIVE: '$if' .*? '$end' -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Islands of interest on DEFAULT_CHANNEL
/*----------------------------------------------------------------------------*/
CALL:
{isBeginOfStatement()}? 'call' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
DELETE:
{isBeginOfStatement()}? 'delete' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
EXPLAIN_PLAN:
{isBeginOfStatement()}? 'explain' COMMENT_OR_WS+ 'plan' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
INSERT:
{isBeginOfStatement()}? 'insert' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
LOCK_TABLE:
{isBeginOfStatement()}? 'lock' COMMENT_OR_WS+ 'table' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
MERGE:
{isBeginOfStatement()}? 'merge' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
UPDATE:
{isBeginOfStatement()}? 'update' COMMENT_OR_WS+ SQL_TEXT+? SQL_END
;
SELECT:
{isBeginOfStatement()}?
(
('with' COMMENT_OR_WS+ ('function'|'procedure') SQL_TEXT+? PLSQL_DECLARATION_END)
| ('with' COMMENT_OR_WS+ SQL_TEXT+? SQL_END)
| (('(' COMMENT_OR_WS*)* 'select' COMMENT_OR_WS SQL_TEXT+? SQL_END)
)
;
/*----------------------------------------------------------------------------*/
// Whitespace
/*----------------------------------------------------------------------------*/
WS: [ \t\r\n]+ -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Any other token
/*----------------------------------------------------------------------------*/
ANY_OTHER: . -> channel(HIDDEN);
/*----------------------------------------------------------------------------*/
// Fragments to name expressions and reduce code duplication
/*----------------------------------------------------------------------------*/
fragment SINGLE_NL: '\r'? '\n';
fragment CONTINUE_LINE: '-' [ \t]* SINGLE_NL;
fragment COMMENT_OR_WS: ML_COMMENT|SL_COMMENT|WS;
fragment SQLPLUS_TEXT: (~[\r\n]|CONTINUE_LINE);
fragment SQL_TEXT: (ML_COMMENT|SL_COMMENT|STRING|.);
fragment SLASH_END: SINGLE_NL WS* '/' [ \t]* (EOF|SINGLE_NL);
fragment PLSQL_DECLARATION_END: ';'? [ \t]* (EOF|SLASH_END);
fragment SQL_END:
EOF
| (';' [ \t]* SINGLE_NL?)
| SLASH_END
;
fragment SQLPLUS_END: EOF|SINGLE_NL;Parser Changes
The start rule file on line 11 in the parser grammar is now defined as a unbounded number of dmlStatment. Each DML statement is a single lexer token. It’s still not possible to produce a parse error with this grammar. We only process DML statements. Everything else is hidden and therefore ignored.
parser grammar IslandSqlParser;
options {
tokenVocab=IslandSqlLexer;
}
/*----------------------------------------------------------------------------*/
// Start rule
/*----------------------------------------------------------------------------*/
file: dmlStatement* EOF;
/*----------------------------------------------------------------------------*/
// Rules for reduced SQL grammar (islands of interest)
/*----------------------------------------------------------------------------*/
dmlStatement:
callStatement
| deleteStatement
| explainPlanStatement
| insertStatement
| lockTableStatement
| mergeStatement
| selectStatement
| updateStatement
;
callStatement: CALL;
deleteStatement: DELETE;
explainPlanStatement: EXPLAIN_PLAN;
insertStatement: INSERT;
lockTableStatement: LOCK_TABLE;
mergeStatement: MERGE;
updateStatement: UPDATE;
selectStatement: SELECT;IslandSQL for VS Code
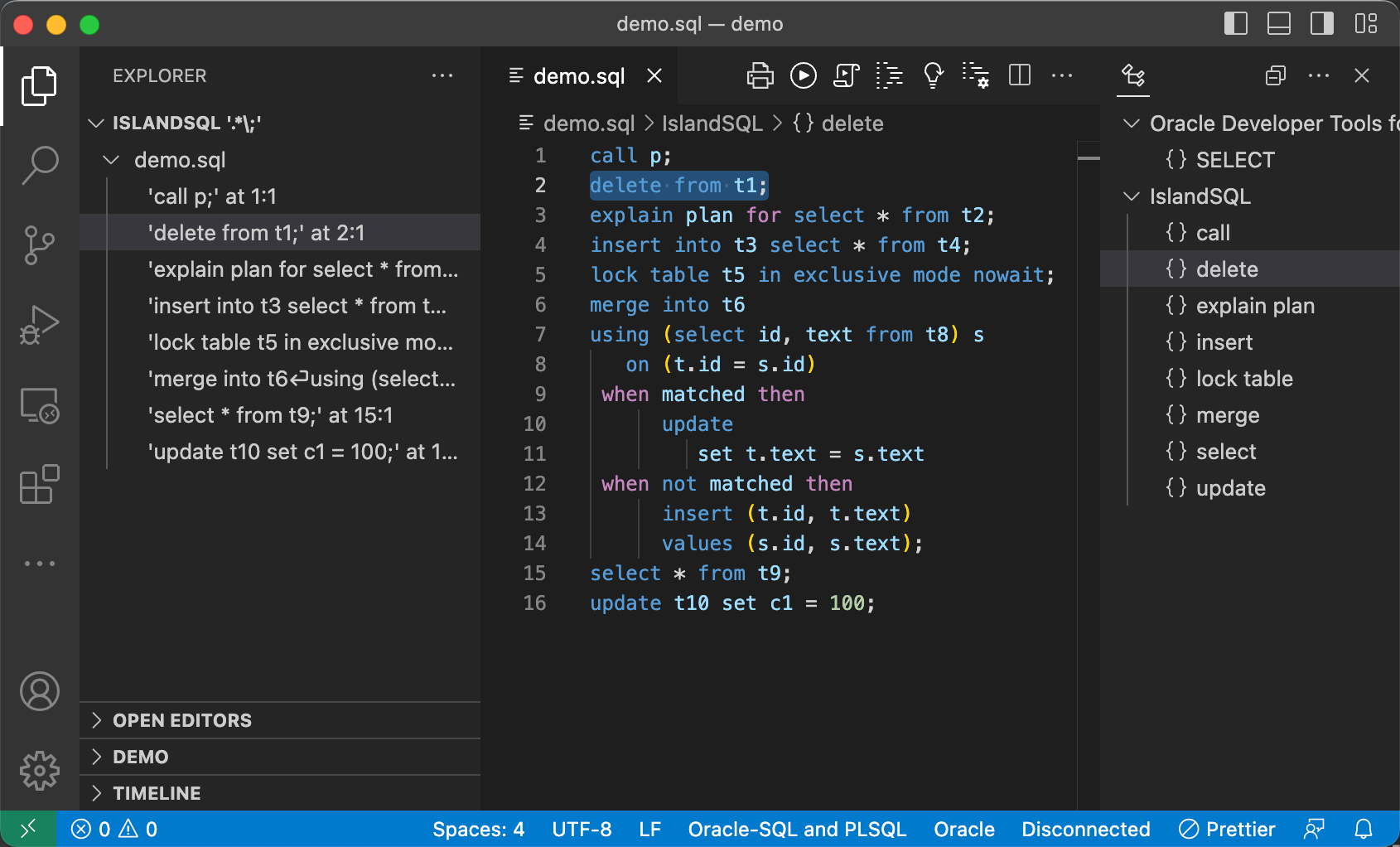
The extension for Visual Studio Code version 0.2.0 finds text in all DML statements and is not limited to select statements anymore. And a symbol for each DML statement is shown now in the outline view.
Outlook
A grammar that can parse all DML statements sounds like something complete. However, this grammar is far from complete. For code analysis, getting a single token for a DML statement is at best a good starting point.
What we need is a more detailed result. For this, we need to move the logic from the lexer to the parser. In the next episode, we will do this with one of the DML statements.
1 Comment
[…] the last episode we extended the IslandSQL grammar to cover all DML statements as single lexer token. Now it’s […]