

Introduction
A customer asked me if it is possible to show unused identifiers in SQL Developer. Since there is no PL/SQL compile warning for that, you might be tempted to say no. But you can always use PL/SQL Cop for static code analysis. Guideline G-1030 deals with variables and constants and guideline G-7140 with procedures and functions. However, in this case, it’s also possible to achieve the same result by tweaking SQL Developer’s preferences for PL/SQL Syntax Colors.
In this blog post, I explain how custom syntax highlighting works in SQL Developer. I use a simple example first and then show how to highlight unused identifiers in SQL Developer.
What Is Syntax Highlighting?
Wikipedia defines syntax highlighting as follows
Syntax highlighting is a feature of text editors that are used for programming, scripting, or markup languages, such as HTML. The feature displays text , especially source code, in different colors and fonts according to the category of terms. (…)
How Does Syntax Highlighting Work?
The next figure illustrates the highlighting process in SQL Developer. The similarities to the formatting process are no accident.
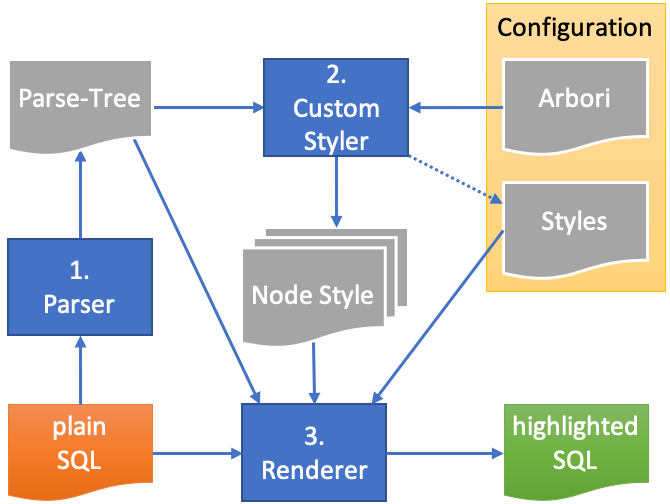
I will explain each step and component in the next chapters.
Please note that these are conceptual components, the actual implementation might look different.
1. Parser
This step is identical to formatting process. The parser reads the unformatted plain SQL or PL/SQL input and generates a parse-tree. The parse-tree is a hierarchical representation of the significant tokens of the input. In other words, there is neither whitespace nor comments in a parse-tree.
Each node in the parse-tree includes the start and end position within the plain SQL input.
2. Custom Styler
The custom styler needs the parse-tree and the Arbori program as input.
Arbori is a query language for parse-trees. See my previous post to learn more about it. The Arbori program is configured in the SQL Developer’s preferences under Code Editor -> PL/SQL Syntax Colors -> PL/SQL Custom Syntax Rules.
2.1. The Results
The custom styler basically only runs the Arbori program. It is responsible for producing two results:
- All custom style names (dotted line to Styles)
to be shown in the preferences underCode Editor->PL/SQL Syntax Colors. Allows the user to configure the foreground and background colours as well as the font style (normal, bold, italic). SQL Developer discovers styles during startup. For changes (new or renamed styles) to take effect you need to restart SQL Developer. - A list of node-style pairs (solid line to Node Style)
to be rendered according to the configured style properties (foreground color, background color and font style).
2.2. The Default Arbori Program
SQL Developer 19.4.0 provides the following default (I removed all multiline comments):
PlSqlColTabAlases: --
[node) c_alias -- Search all the nodes in the parse tree which are column aliases
| [node) identifier -- Or nodes with identifier payload,
& [node-1) query_table_expression -- which younger siblings are labeled with table names
-> -- The semantic action symbol (to trigger syntax highlighting).
; -- End of the rule
PlSqlLogger:
[pkg) name
& (?pkg = 'DBMS_OUTPUT' | ?pkg = 'APEX_DEBUG' |
?pkg = 'LOG' | ?pkg = 'logger' -- pattern match is case insensitive
)
& (pkg^ = node | pkg^^ = node)
& [node) procedure_call
->
;The query names defined on line 1 (PlsqlColTabAlases) and line 8 (PlSqlLogger) define the style name used in the preference dialog under Code Editor -> PL/SQL Syntax Colors.
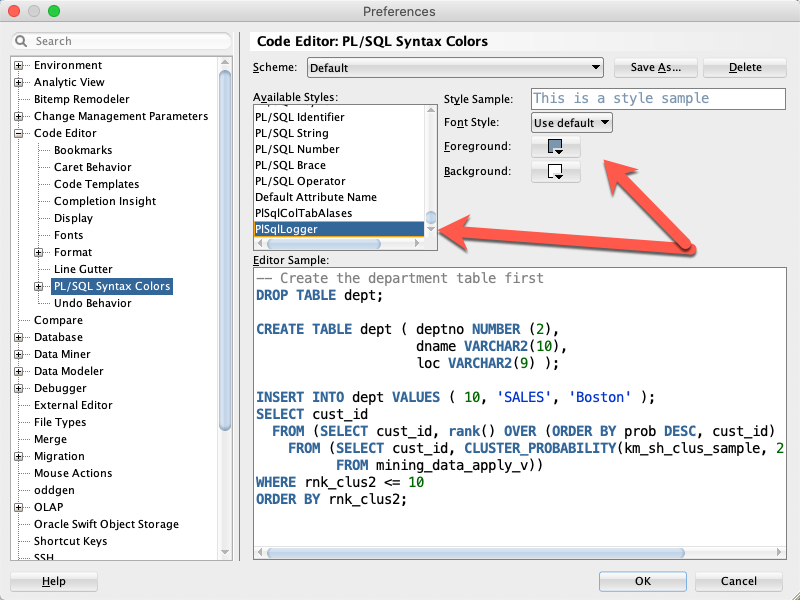
2.3. Configuring Styles
This screenshot shows how the PlSqlLogger style is configured.
2.4 JavaScript Callback Functions
The default Arbori program uses predefined Java callback functions in the CustomSyntaxStyle class.
Since SQL Developer 19.2.0 you can use embedded JavaScript callback functions. As a result Java callback functions are not necessary anymore.
Here’s an example how to change PlSqlLogger query to use a JavaScript callback function:
PlSqlLogger:
[pkg) name
& (?pkg = 'DBMS_OUTPUT' | ?pkg = 'APEX_DEBUG' |
?pkg = 'LOG' | ?pkg = 'logger' -- pattern match is case insensitive
)
& (pkg^ = node | pkg^^ = node)
& [node) procedure_call
-> {
var node = tuple.get("node");
struct.addStyle(target, node, "PlSqlLogger");
}
;Important is line 10. It shows how to add a style for a node in the parse-tree.
2.5 JavaScript Global Variables
The following variables are provided. You should know them when writing JavaScript callback functions.
target- instance of
oracle.dbtools.parser.Parsed, that’s the complete parse-tree. The following properties and methods are helpful:- src or getSrc() – list of
orace.dbtools.parser.LexerToken. Indexed by node number. - root or getRoot() – the root node.
- input or getInput() – the source text.
- src or getSrc() – list of
- instance of
tuple- instance of
HashMap<String, oracle.dbtools.parser.ParseNode>. It contains an Arbori query result row. The structure is indexed by the query node names. E.g. for the previousPlSqlLoggerquery you can accesspkg,node,pkg^,pkg^^via thegetmethod ofHashMap. Basically, these are the result columns shown when you execute a query in the Arbori editor.
- instance of
struct- instance of
oracle.dbtools.raptor.plsql.language.CustomSyntaxStyle, that’s the custom styler. You need only this method:addStyle(Parsed target, ParseNode node, String styleName)
- instance of
2.6 Important Classes
Two classes are really important. I’ve listed them with some properties and methods that you might need:
ParseNodefrom– start position of the node in the parse-tree.to– end position of the node (half-open interval, this means the last including position isto-1).parent– parent node.descendants()– list of all child nodes (including their children, recursively).intermediates(int from, int to)– list of all nodes in the half-open interval.toString()– string representation of the node including all symbols.printTree()– prints a nicely formatted parse-tree on the console. This textual format is used in the Arbori documentation.
LexerTokencontent– the token represented as string.begin– start position in characters of the token in the input string.end– end position in characters of the token in the input string (half-open interval).type– type of the token.toString()– string representation of the token.
2.7 Overriding Queries for Internal Styles
The custom styler is not designed to override queries for built-in styles such as PL/SQL String.
However, you can define additional styles. Custom styles are applied at the very end of the process. As a result, you can override previously applied styles.
3. Renderer
The renderer is attached to the PL/SQL editor. It runs in the background and needs access to the plain text, the parse tree, the list of node-style pairs and the settings (foreground color, background color, font style) for each style.
Now, the renderer can loop through the internal and custom list of node-style pairs and apply the requested style to all tokens within the node. The result is a nicely highlighted document.
Example 1 – Extending PlSqlLogger
Setup
I use the default configuration of SQL Developer 19.4.0 including the standard Arbori program.
Default Highlighting Result

The result looks good. Wait, no, the line two should be displayed in grayish color, as defined for the PlSqlLogger style.
Expected Highlighting Result
That’s what we expect:

In fact, it works as expected if I omit the sys prefix. However, it is good practice to use it. Why? See the Trivadis PL/SQL & SQL Coding Guidelines for G-7510.
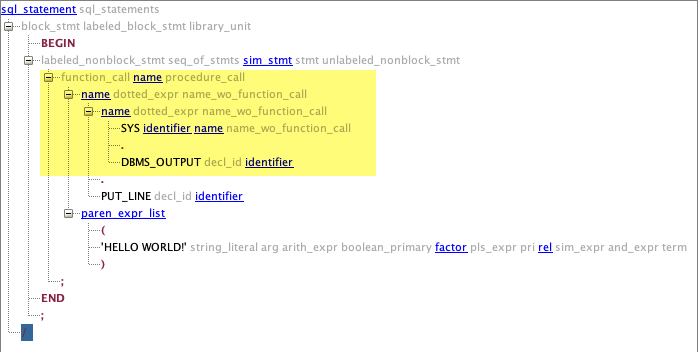
Code Outline
SQL Developer’s code outline is a representation of the full parse-tree. Disable all filters to show all nodes.
Arbori Editor
Type arbori in the search field and press enter to open the Arbori editor. Copy the PlSqlLogger query from the preferences into the Arbori editor and press run.
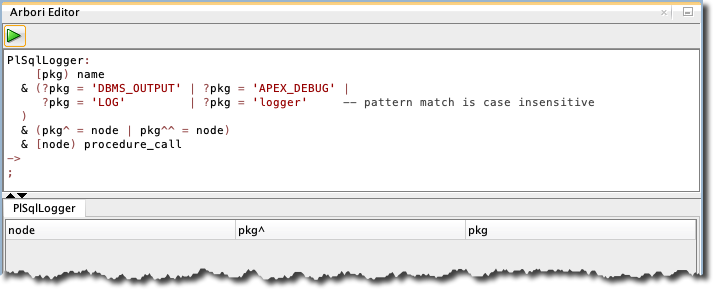
The query returns no result.
Why? Because [pkg) expects a node of type name. But when you look in the outline you see that DBMS_OUTPUT is a decl_id and also an identifier. But it is not a name.
Fix Arbori Program
Here’s the fix:
PlSqlLogger:
[pkg) identifier
& (?pkg = 'DBMS_OUTPUT' | ?pkg = 'APEX_DEBUG' |
?pkg = 'LOG' | ?pkg = 'logger' -- pattern match is case insensitive
)
& (pkg^ = node | pkg^^ = node | (pkg^^^ = node & ?pkg-1-1 = 'SYS'))
& [node) procedure_call
->
;On line 2 I expect an identifier for [pkg).
And on line 6 I added the or condition (pkg^^^ = node & ?pkg-1-1 = 'SYS'). This means that the grand-grandparent of the node named pkg must be the same as the node named node. node must be of type procedure_call (see line 7). Furthermore, I said that the name of the previous-previous node of pkg must be SYS. That’s it.
Now you can copy & paste this change into the Arbori editor to test it. Afterwards, you can copy the change to the Arbori program in the preferences to apply the change.
Example 2 – New UnusedIdentifier
Setup
I use the default configuration of SQL Developer 19.4.0 including the changes made in the previous example.
Default Highlighting Result

The result looks good. However, SQL Developer does not provide information about unused variables, constants, functions and procedures. The right solution would be to use the mechanism as for SQL injection detection. But that’s not (yet) possible.
Expected Highlighting Result
Therefore I’d like to highlight the unused variables and procedures like this:

The comments in the code example explain the highlighting result.
Register Style (Requires Restart)
This Arbori query finds all PL/SQL blocks to be examined:
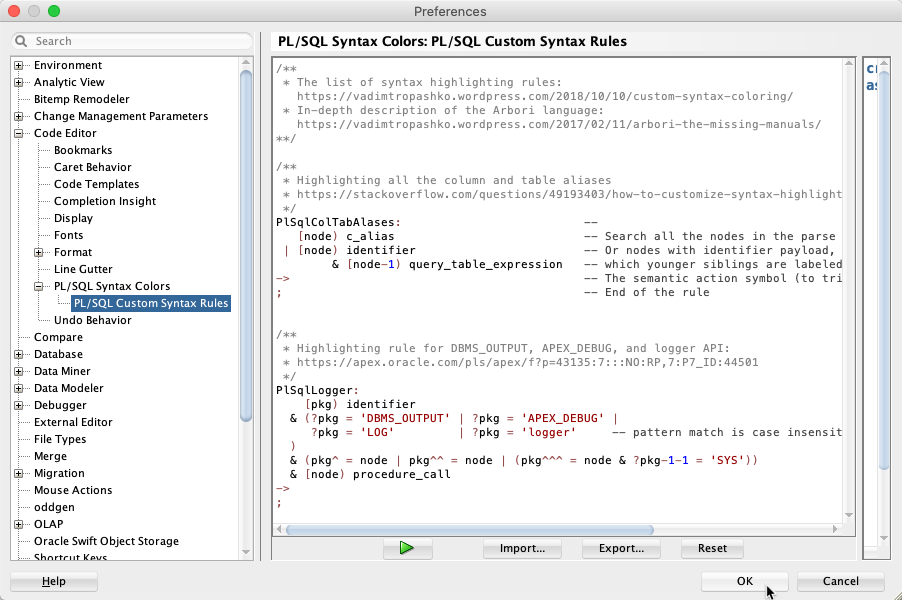
UnusedIdentifier:
[node) seq_of_stmts & [node-1) 'BEGIN' & ([node+1) exception_handlers_opt | [node+1) 'END')
;Add it to the Arbori program in the preference dialog as shown here:
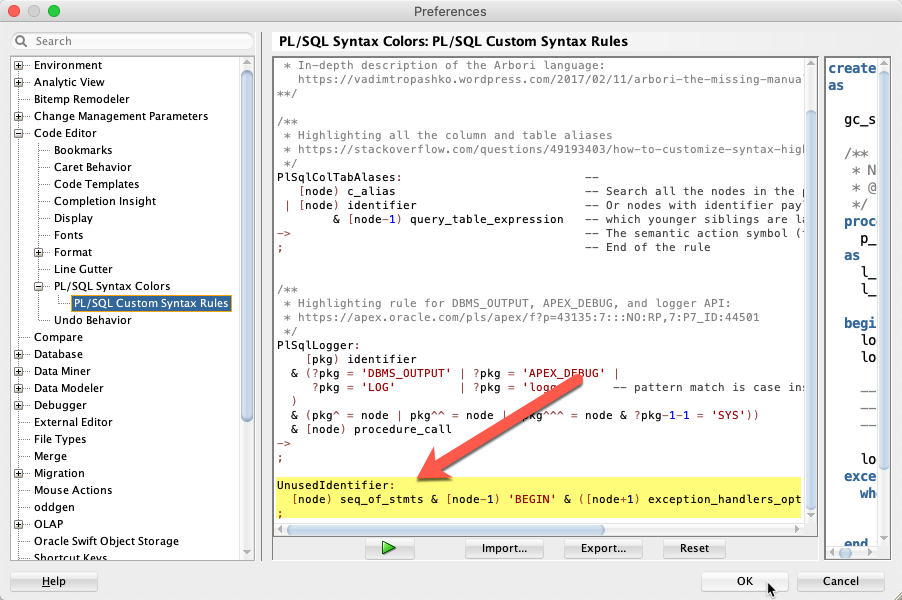
Press OK and restart SQL Developer.
Configure Style
After restarting SQL Developer the new style UnusedIdentifier is shown in the preferences:
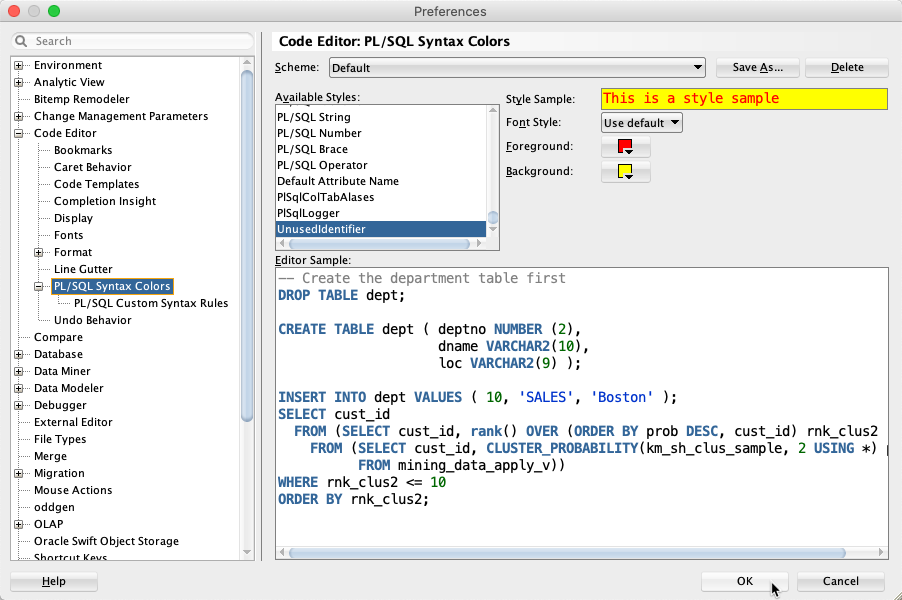
Configure the font style and the foreground and background colors the way you like it.
Now we need to tell SQL Developer where to apply this style.
Arbori Program
This program does all the magic. Please note that the query is the same as before. I’ve just added the JavaScript callback function. In fact, it’s more a JavaScript program now.
UnusedIdentifier:
[node) seq_of_stmts & [node-1) 'BEGIN' & ([node+1) exception_handlers_opt | [node+1) 'END')
-> {
var countParentSymbol = function(inParentNode, inChildNode, symbol) {
var count = 0;
var parents = inParentNode.intermediates(inChildNode.from, inChildNode.to);
for (j=0; j<parents.size(); j++) {
var parent = parents.get(j);
if (parent.toString().contains(symbol)) {
count++;
}
}
return count;
}
var populateMaps = function(inNode) {
if (inNode != null) {
var children = inNode.descendants();
for (i=0; i<children.size(); i++) {
var child = children.get(i);
if (child.toString().contains("decl_id")) {
if (countParentSymbol(inNode, child, "decl_list") == 1) {
if (countParentSymbol(inNode, child, "seq_of_stmts") == 0) {
var token = target.src[child.from].content.toLowerCase()
usageMap.put(token, 0);
nodeMap.put(token, child);
}
}
}
}
}
}
var checkStatements = function(inNode) {
var children = inNode.descendants();
for (i=0; i<children.size(); i++) {
var child = children.get(i);
if (child.toString().contains("identifier")) {
var token = target.src[child.from].content.toLowerCase();
var usages = usageMap.get(token);
if (usages != null) {
usageMap.put(token, usages + 1);
}
}
}
}
var checkExceptions = function(inNode) {
if (inNode != null) {
if (inNode.toString().contains("exception_handlers_opt")) {
checkStatements(inNode);
}
}
}
var reportUnusedIdentifiers = function() {
var iterator = usageMap.keySet().iterator();
while (iterator.hasNext()) {
var key = iterator.next();
var usages = usageMap.get(key);
if (usages == 0) {
struct.addStyle(target, nodeMap.get(key), "UnusedIdentifier");
}
}
}
var usageMap = new java.util.HashMap();
var nodeMap = new java.util.HashMap();
var node = tuple.get("node");
populateMaps(node.parent);
checkStatements(node);
checkExceptions(tuple.get("node+1"));
reportUnusedIdentifiers(node);
}
;I’ve divided the logic into 5 local functions. I call them at the end of the program. They should be more or less self-explanatory. But surfing through a parse-tree has a certain basic complexity. You find the important call for the code styler on line 58.
Now you can replace the UnusedIdentifier query in the PL/SQL Custom Syntax Rules preferences dialog with the code above. Press OK and unused identifiers are highlighted in the PL/SQL editor.
Summary
The features provided by SQL Developer for syntax highlighting are really extensive and very good. I have never seen anything like this in any other IDE. My second example is probably not a good use case for syntax highlighting. But it clearly shows that custom syntax highlighting in SQL Developer is almost limitless.
Personally, I would like to see comment nodes in the parse-tree as well. This would allow us to distinguish between hints and comments, for example.
Thanks, SQL Developer team. Well done!
1 Comment
[…] this blog post I covered how syntax highlighting works in SQL Developer and how to add a custom styler. If you are […]