

Since February 13 2019 Oracle Database 19c has been available. I blogged about this feature here and here. Time for an update. So, what’s new in 19c regarding the MemOptimized Rowstore?
Fast Lookup Works with JDBC Thin Driver
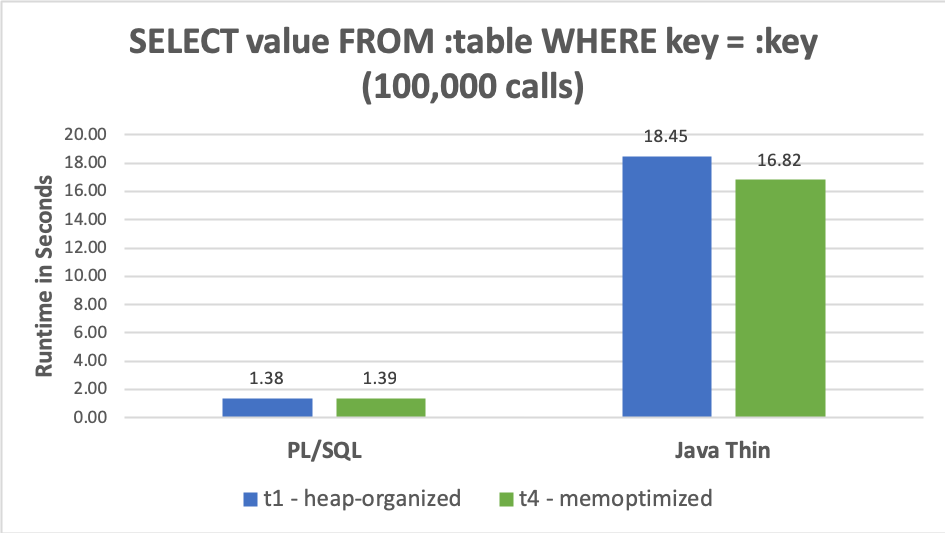
I listed 16 prerequisites for the MemOptimized Rowstore in this blog post. The last one – “The query must not be executed from a JDBC thin driver connection. You have to use OCI, otherwise the performance will be really bad.” does not apply anymore. This “bug” is fixed in 19c. Here are the JDBC thin driver results of the test program listed in this blog post:
# t1 - heap table
run #1: read 100000 rows from t1 in 18.602 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #2: read 100000 rows from t1 in 17.723 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #3: read 100000 rows from t1 in 18.834 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #4: read 100000 rows from t1 in 18.039 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #5: read 100000 rows from t1 in 18.711 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
# t4 - memoptimized heap-table
run #1: read 100000 rows from t4 in 16.696 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #2: read 100000 rows from t4 in 16.671 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #3: read 100000 rows from t4 in 16.952 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #4: read 100000 rows from t4 in 16.805 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.
run #5: read 100000 rows from t4 in 17.627 seconds via jdbc:oracle:thin:@//localhost:1521/odb.docker.See, the runs for t4 are the fastest because they used memopt r lookups instead of consistent gets. BTW, the absolute runtime values of these tests are not important or representative, they vary a lot depending on the Docker environment that I use. However, I consider the relative difference between the t1 and t4 as relevant and conclusive. The next graph visualizes the results. I also added the results for the PL/SQL runs to this graph. It clearly shows that if you can do it within the database, you should do it.
I also run this test for 18.5.0.0.0. It looks like this bug has not been fixed in 18c yet.
Fast Ingest
This new 19c feature consists of two parts. The usage is best described in the Database Performance Tuning Guide.
First, the table must be enabled for memoptimized write using the memoptimize_write_clause. You can do that in the create table or the alter table statement. Here’s an example:
CREATE TABLE t5 (
key INTEGER NOT NULL,
value VARCHAR2(30 CHAR) NOT NULL,
CONSTRAINT t5_pk PRIMARY KEY (key)
)
SEGMENT CREATION IMMEDIATE
MEMOPTIMIZE FOR WRITE;One way to trigger fast ingest is to use an insert hint. Here’s an example:
BEGIN
FOR r IN (SELECT * FROM t4 WHERE key between 10001 and 20000) LOOP
INSERT /*+ memoptimize_write */ INTO t5 VALUES r;
END LOOP;
END;
/There is no commit in this anonymous PL/SQL block. In this case an additional commit statement would just slow down the processing. The insert statements are treated like asynchronous transactions. This mechanism is called „delayed inserts“. The rows to be inserted are collected in the large pool and processed asynchronously in batches using direct path inserts. That will happen eventually. However, you can call dbms_memoptimize_admin.writes_flush to force the rows in the large pool to be written to disk.
Fast ingest is much more efficient than a series of conventional single transactions. But, there are some disadvantages to consider.
- Data loss in case of a crash of the database instance
- Delayed visibility of inserted data
- Delayed visibility of errors
The first two are simply the price to optimize the insert performance of multiple clients. However, the last one is interesting. Where are errors reported in this case and how do we deal with them?
Here’s an example.
SELECT * FROM t5 WHERE key IN (10001, 20001);
KEY VALUE
---------- ------------------------------
10001 PAST7NL2N2W8K9ESS7BZWSI
BEGIN
FOR r IN (SELECT * FROM t4 WHERE key IN (10001, 20001)) LOOP
INSERT /*+ memoptimize_write */ INTO t5 VALUES r;
END LOOP;
dbms_memoptimize_admin.writes_flush;
END;
/
PL/SQL procedure successfully completed.
SELECT * FROM t5 WHERE key IN (10001, 20001);
KEY VALUE
---------- ------------------------------
10001 PAST7NL2N2W8K9ESS7BZWSI
20001 4IMKI9RLBTV7
Fast ingest persisted the non-existing row with the key 20001. But the row with the existing key 10001 was ignored. Somewhere an ORA-00001: unique constraint violated must have been thrown. But right now I do not know If it was just swallowed or stored somewhere (I have not found the trace file mentioned in Database Concepts). If ignoring is the right way to deal with such errors, then we are all set. Otherwise, we have to think a bit more about it.
2 Comments
Exadata / Engineered systems only ?
In the first post I listed the systems for 18c:
For 19c this has not changed.