

1. Introduction
The Pink Database paradigm (PinkDB) is an application architecture for database-centric applications. It focuses on relational database systems and is vendor-neutral. The principles are based on the ideas of SmartDB, with some adaptions that make PinkDB easier to apply in existing development environments. An important feature of a PinkDB application is that it uses set-based SQL to conserve resources and deliver the best performance.
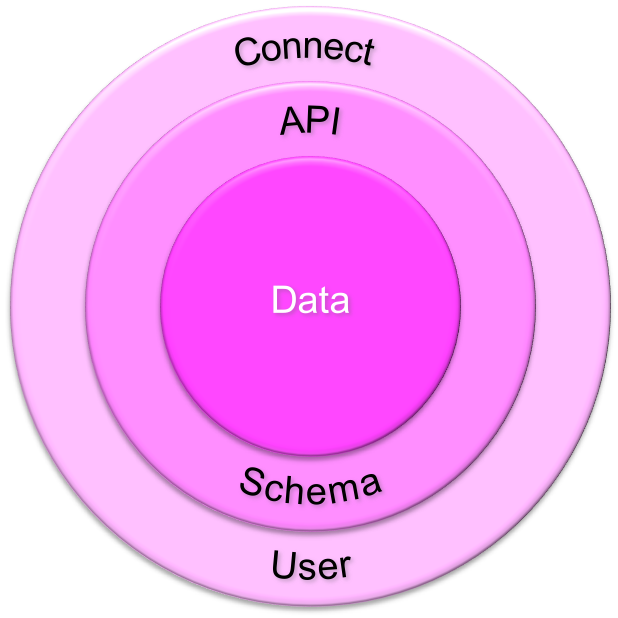
Connect User
The connect user does not own objects. No tables. No views. No synonyms. No stored objects. It follows the principle of least privileges.
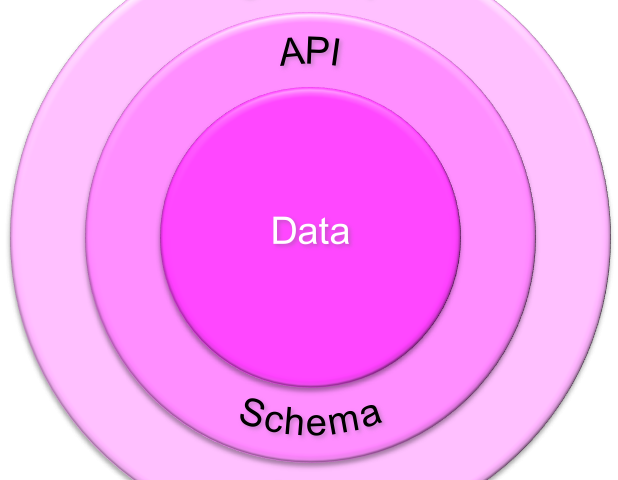
API Schema
The API schema owns the API to the data. Access is granted on the basis of the principle of least privileges. The API consists of stored objects and views, but no tables.
Data
The data is stored in a data model using the features of the underlying database system for consistency. It is protected by the API and processed by set-based SQL for best performance.
2. Features
An application implementing PinkDB has the following features:
- The connect user does not own database objects
- The connect user has access to API objects only
- The API consists of stored objects and views
- Data is processed by set-based operations
- Exceptions are documented
2.1. The connect user does not own database objects
The connect user is used by application components outside of the database to interact with the database. It is configured for example in the connection pool of the middle-tier application.
The connect user must access only the APIs of the underlying database applications. It must not own database objects such as tables, views, synonyms or stored objects.
The principle of least privileges is followed.
This is 100 percent identical to SmartDB.
2.2. The connect user has access to API objects only
Database tables are guarded behind an API. The connect user must not have privileges to access objects that are not part of the API, e.g. via SELECT ANY TABLE privileges or similar.
The principle of least privileges is followed.
2.3 The API consists of stored objects and views
The API schema owns the API to the data. Access is granted on the basis of the principle of least privileges. The API consists of stored objects and views, but no tables.
2.4 Data is processed by set-based operations
The data ist stored in a data model using the features of the underlying database system for consistency. It is not necessary to store tables, indexes, etc. in a dedicated schema. But it is mandatory, that the data is protected by the API.
Set-based SQL ist the key to good performance. It means that you are using the database as a processing engine and not as a data store only. You should avoid row-by-row processing when set-based SQL is feasible and noticeably faster. This means that row-by-row processing is acceptable, e.g. to update a few rows via GUI, but not for batch processing where set-based operations are by factors faster. Using stored objects for batch processing simplifies the work. Set-based processing becomes natural.
You should make it a habit to minimize the total number of executed SQL statements to get a job done. Less loops, more set-based SQL. In the end, it is simpler. You tell the database what you want and the optimizer figures out how to do it efficiently.
2.5 Exceptions are documented
All these features are understood as recommendations. They should be followed. Without exceptions. However, in real projects, we have to deal with limitations and bugs and sometimes it is necessary to break rules. Document the reason for the exception and make sure that the exception does not become the rule.
3. Differences to SmartDB
SmartDB is targeting PL/SQL and therefore focusing on Oracle Databases. PinkDB is vendor agnostic and can be applied on SQL Server, Db2, Teradata, EnterpriseDB, PostgreSQL, MySQL, MariaDB, HSQL, etc. This does not mean that just a common superset of database features should be used, quite the contrary. Use the features of the underlying systems to get the best value, even if they are vendor-specific.
The API in SmartDB consists of PL/SQL units only. No exceptions. PinkDB allows views. In fact they are an excellent API for various use-cases. For example, reporting tools using SQL to access star schemas or using an MDX adapter to access logical cubes based on analytic views. APEX is another example. You develop efficiently with APEX when your reports and screens are based on views (or tables). Using stored objects only to access Oracle database sources is working against the tool. However, you have to be careful. Using views only can be dangerous and most probably will violate sooner or later the “data is processed by set-based operations” feature, if you do not pay attention. Other examples are applications built with JOOQ. JOOQ makes static SQL possible within Java. The productivity is comparable to PL/SQL. It’s natural to write set-based SQL. These examples show that defining NoPlsql (NoStoredObjects) as the opposite of SmartDB is misleading since it describes something bad. NoPlsql is not bad per se. It really depends on how you use the database. If you use it as a processing engine then this cannot be bad. In fact, it is excellent. This is probably the biggest difference between SmartDB and PinkDB.
SmartDB has this weird requirement that all SELECT, INSERT, UPDATE, DELETE and MERGE statements must be written by human hand (within PL/SQL). No generators are allowed. PinkDB welcomes generators to increase the productivity and consistency of the result.
The last difference is transaction control statements. SmartDB enforces them to be part of the PL/SQL API. PinkDB allows the use of COMMIT and ROLLBACK outside of the database. However, if a stored object call is covering the complete transaction, it should take also responsibility for the final COMMIT.
SmartDB and PinkDB have the same ancestors. I see PinkDB as the understanding sister of her wise, but sometimes a bit stubborn brother SmartDB.
4. Related Resources
As I said, PinkDB and SmartDB are related. That’s why all SmartDB documents are also interesting for PinkDB. Steven Feuerstein is maintaining a SmartDB Resource Center. You find a lot of useful information and links there. I highly recommend looking at Toon Koppelaar’s excellent video and slide deck. Toon really knows what he is talking about. Would you like to know if your database application is SmartDB compliant? Then see my previous blog post. There’s a script you can run to find out.
19 Comments
Philipp,
Thank you very much for this definition. In addition to its merits, it opens another door for discussion. Allow me to share the thoughts this post inspires.
The word “application” might be taken to mean “OLTP application”, which is too restrictive. Instead of “application architecture”, I would prefer to say “data access architecture” so as to include all uses of the data.
“Production” data is used for:
OLTP applications
REST services (or equivalent)
streaming access
batch (data exchange between production databases)
ETL extraction (to data warehouses)
The architecture should take into account all types of access, including when two databases are involved. There is also the case of an OLTP application that orchestrates more than one data source! This requires a transaction manager in the application layer.
Depending on the use case, three types of access may be appropriate:
row by row
“bulk” (several rows at a time)
set-based
Views: in Oracle, I would accept read-only views, but restrict data modifications to stored procedures. Do you accept changing data through views? I guess so, because of APEX.
COMMIT / ROLLBACK in the stored object: I don’t see the need in Oracle, because of statement level atomicity. If an application calls an API that does a logical unit of work, all the changes will be mode or none of them will – as long as the API does not commit or roll back itself! Since atomicity is respected, the application can commit after one unit of work or ten, who cares?
Finally, anyone defining an “application architecture” should provide some detail about the data access layer in the application: guidelines for connection pools, caching “prepared statements”, using bind variables, setting fetch sizes and such. A poorly configured application could bring a SmartDB database to its knees.
Thanks again for this post!
Best regards,
Stew
Hello Stew,
Thank you for the detailed feedback. Here are my answers:
The term “application” is not restricted to OLTP. I considered OLTP and BI applications including ETL/ELT and data marts. But I see the issue that the PinkDB definition is just covering a subset of the whole application stack. Naming that subset is a challenge and I think it is a bit more than just the “data access” but certainly less than the whole application. I’m still looking for the right term. In the meantime I keep the broader term “application”.
I agree. This is why PinkDB allows the COMMIT/ROLLBACK outside of the database. If you are using a 2PC, or a best effort 1PC commit, is left open. PinkDB just covers a single database including database links.
Why do you think it is necessary to distinguish between set-based and bulk? – Is there more than passing a “set of rows” (some kind of collection, XML, JSON or even an input table) to an API? – Is “bulk” not covered by the term “set-based”?
Yes. Read-only views and stored procedures for write operations are indeed a good solution. But as you said, for APEX and similar tools it is easier to have updatable views. Either through default behavior or via instead-of-trigger. As soon as you’re doing more than a few write operations via these views you need a write API (set-based/with bulk capabilities). Not implementing one would violate the feature “data is processed by set-based operations”. It depends on the use case, if a dedicated write procedures are required. But I fully agree that they are the cleaner approach.
It depends on the client technology and use case. To avoid locking issues you want that the transaction is either committed or rollbacked at the end. Fat clients may use a stateful connection and delay the rollback/commit even for simple changes. I’ve seen that in the past. This is certainly unwanted. Another example: an ETL/ELT load via a stored procedure. I do not see a reason why such a procedure should not commit/rollback at the end (it even may need to do so in between as well).
I see your point. I guess the answer is again use case specific. In a batch process I’d like to minimize the number of commits. For OLTP applications I’d like to commit as soon as possible.
Do you think PinkDB should define policies for connection pools, etc., or do you stress the fact that PinkDB does not cover the entire application stack?
You’re welcome!
Cheers,
Philipp
Awesome post Philipp.
This is a great balance between utopian goals and the real world where ultimately we aim to get people closer to the ideal configuration, whilst understanding that sometimes architecture, software versions, politics, time and budgetary pressures means we must compromise.
Cheers,
Connor
Thanks Connor. I appreciate and fully agree.
Philipp,
your thoughts on updatable views are
… As soon as you’re doing more than a few write operations via these views you need a write API (set-based/with bulk capabilities). ….
Updatable views already support set-based/bulk-operations, since they simply can be used within SQL ? – what do I miss here ?
Thanks,
Matthias
Example 1
Let’s look at the following example:
Let’s assume this statement updates 1000 rows. Hence we updated 1000 rows in one go. Looks good, right? It’s possible, but we cannot be sure. If something like that is defined behind the scenes
CREATE OR REPLACE TRIGGER some_trg INSTEAD OF UPDATE ON some_view BEGIN ... UPDATE some_table SET ...; ... END; /then this leads to additional 1000 SQL statement executions. A single SQL leads to 1001 SQL executions. It can get even worse if the trigger is doing set-based operations on views with other instead-of-triggers. This is not the kind of set-based execution we want. It’s in fact row-by-row and slow.
Example 2
Imagine a GUI where I can show a lot of rows in a singe page as a result of a query. With
ctrl-aI mark all rows, change the value of a column for all selected rows in one go and press the save button. What happens behind the scenes? A single update likeor an update per row like
FOR i in 1..n LOOP UPDATE some_view SET some_column = :1 WHERE id = :2 END LOOP;You have to know the technology stack to answer that question. But it is not uncommon to see the second option, probably updating all columns, even if they have not been changed. This is not set based, even if the underlying view has no instead-of-trigger and would allow set-based operations.
This is what I meant with
Read-only views would make the contract clearer from the beginning, but will most probably lead to higher implementation costs. That’s why PinkDB allows you to use updatable views as long as you are not violating feature 2.4.
I hope that made it clearer.
Regarding your update examples, especially #2, I would not take this approach. You don’t know how stale the data may be. I would send the original and changed row(s) as collections to an “update” XAPI. It would load the original rows into one collection and the updated rows into another. Reselect (for update) the row(s) into a third and make sure nothing has changed. If so, bulk update and commit. If not, rollback and return an error saying the data is stale. None of this needs dynamic SQL.
The example is simplified. Of course you should implement an optimistic locking mechanism.
Hi Philipp,
… Example 1 … This is not the kind of set-based execution we want. It’s in fact row-by-row and slow. …
ok, it’s row-by-row, but not necessarily slow.
gives
which is of course more work than
But it is bulk and set-based.
And I don’t see how you implement an API here to do this better ? Can you show me ?
In fact, I like the idea of using views and instead-of-triggers on these views as part of an API, since set-based-operations are out-of-the-box available there, and I quite often use that.
I have made the experience that performance penalty isn’t such big in most cases, especially in newer versions of Oracle(>=12).
An experiment is the right thing to do. I’m sure you may imagine the impact on runtime performance when you do much more work in the instead of trigger.
Regarding the API to enable set-base processing while minimizing the total number of executed SQL statements. For this example it is simple. The procedure could look like this
CREATE OR REPLACE PROCEDURE p1 ( in_increment_j INTEGER, in_for_i_less_or_equal INTEGER ) IS BEGIN UPDATE some_table SET j = j + in_increment_j WHERE i <= in_for_i_less_or_equal; END p1; /But this is too simplistic. Let’s improve the API regarding query criteria, by passing a list of primary keys. To solve such a problem, I’ve seen the following:
a) Two-Step-Approach
1. populate a work table (through a view) with the information required for the second step
2. process the data via a simple procedure call passing a set identifier for the work table
b) Single-Step-Approach
Pass a collection to the procedure. Collection types are possible, but it is not that easy to work with in a lot of client technologies. Using LOBs is easier. Passing a format which can be used in SQL simplifies the processing. So it’s either XML or JSON. I’d go with JSON if your client can deal with it. So the new procedure could look like this:
CREATE OR REPLACE PROCEDURE p2 ( in_increment_j INTEGER, in_json CLOB -- e.g. '[1,2,3]' ) IS BEGIN UPDATE some_table SET j = j + in_increment_j WHERE i IN ( SELECT i FROM JSON_TABLE( in_json, '$[*]' COLUMNS i INTEGER path '$' ) ); END p2; /The next anonymous PL/SQL block shows that the query options are not limited.
DECLARE l_json CLOB; BEGIN SELECT json_arrayagg(some_column RETURNING CLOB) INTO l_json FROM some_view WHERE some_column <= 5000; p2(100, l_json); END; /Philipp, with all due respect (and a ton of appreciation) to Bryn and Toon for pretty much defining what SmartDB means, it is a paradigm, not an implementation. As such, I can’t see it being vendor-specific. Can a vendor own an idea?
Even if they decide that in order for something to meet their definition of SmartDB, it must have a quality that can currently only be implemented in Oracle, that doesn’t make it an Oracle-only paradigm (to me). It just means other vendors need to catch up on features if they want to embrace this idea.
That said, there are some perceived restrictions in the definition of SmartDB that makes it difficult to implement. If your intent for PinkDB is just to relax some of of the requirements that make SmartDB impractical, that works for me.
One of my perceived issues was it not allowing Views to be exposed. My application is a mix of OLTP and a Data Mart. When the user is querying data, they are querying large fact tables created by batch ETL processes that processed budgetary transactions created in the OLTP part of the application. If you listen to the April 17th Office Hours recording starting at 31:50 and then paying particular attention from 33:50 to 36:45, my interpretation of what was said is that I can implement some read-only views for APEX or Node.js (our two potential front-end solutions) to provide these “BI” lookups without breaking their rules of SmartDB.
I watched the video and transcribed the part between 35:50 and 36:31 to text. Bryn said the following:
He is splitting the system into two subsystems. The “data changing subsystem” being SmartDB and the “query-only subsystem” being something else, but for sure not SmartDB. The aggregated system is not SmartDB, but it is PinkDB.
Views are not tolerated as part of the API in SmartDB.
Hi Philipp,
Even though #SmartDB is very well possible with EnterpriseDB Postgres (EDB Postgres Advanced Server), I like the idea of a vendor agnostic approach even better.
It is the smarter idea to use the data management engine to do this, even if you are not in the circumstances to invest big money in your data management engine. In fact, it makes even more sense, as you are probably running leaner projects anyway, that need the additional benefit of a concept like #PinkDB.
Thanks for the write-up, thank you for sparking the discussion and I look forward to discussing this further with you and the #PinkDB peers!!
Cheers,
Jan
Thank you, Jan.
Yes, EDB Postgres Advanced Server is indeed very well suited for SmartDB, since SPL is PL/SQL compatible. And of course I can imagine scenarios where PinkDB is easier to implement.
See you in Nuremberg.
Philipp
[…] I usually only have a vague idea of the title. I’m usually going to change it more than once. The Pink Database Paradigm (PinkDB) was no different. An early version of the title was based on the acronym “uDBasPE” for […]
[…] And I will use this view-API in a JOOQ application. This application will fully comply with the Pink Database Paradigm (PinkDB). This means the application uses the database as processing engine, executes set-based SQL and […]
[…] on a larger scale. The solution is simple. Use the database as processing engine as recommended by PinkDB and […]
Hi Philipp,
sorry for commenting on this somewhat older post. I totally agree with your thoughts and would like to add one thought from my point of view: Validation of data.
It is not mentioned in your post but I guess you feel that validating data is the duty of the stored procedures in the API schema layer.
Based on the experience I made I feel that its worthwhile separating the validation logic from the persistence logic logically to enable the connect user layer to validate but not persist data. As a use case think about APEX validation logic which lives in a separate life cycle from the persistence flow.I believe it is important to point this out as validation of data is often seen as the duty of the application layer, especially in low code tools like APEX. This is not feasible in my opinion as this will double the validation logic or, if you don’t validate within the data layer, open the possibility to write non plausible data into the data layer. Writing validation code in the application layer may even force you to grant access to data that is only needed for validation purposes, violating the least possible privilege concept.
Thank you Jürgen. Comments are welcome anytime.
IMO you should use constraints whenever possible/feasible to validate data. Not null, check and integrity constraints. Everything else can be validated between API and data layer. The database must be responsible for the data consistency. It should not be possible to create invalid data by using the API. No matter which client is used.
I agree that there is a certain logic which is usually duplicated outside of the database to validate the data. You could make this logic reusable as part of the database API. However, this comes with a price tag. A network roundtrip for every validation check. In a GUI I usually want to check as early as possible. This means on a field base, if possible. Sometimes even during entry of a field (filtering valid values). This kind of checks are typically written in a different way than the checks within the database that are capable to handle one ore more rows. Sometimes there are not even explicit checks. For example the values for a combobox field. The GUI framework prohibits the entry of a wrong value. However, on-save the database checks it nonetheless.
To reduce the duplication of validation logic I would keep the logic in the database. The database validates 100%. Some parts need to be duplicated to improve the user experience and let the user know as early as possible about the validation failures. However, some parts will be validated delayed. When pressing save. This is acceptable quite often in my experience.
I can live with “some” duplicated logic as long as the integrity of the database is not compromised.